Chapter 1 Introduction to Large Language Model LLM
1.1 Introduction to Large Language Model (LLM)
Large Language Model (LLM), also known as large language model, is an artificial intelligence model designed to understand and generate human language.
LLMs typically refer to language models containing tens of billions (or more) of parameters that are trained on massive amounts of text data to gain a deep understanding of language. At present, well-known foreign LLMs include GPT, LLaMA, Gemini, Claude and Grok, etc., and domestic ones include DeepSeek, Tongyi Qianwen, Doubao, Kimi, Wen Xinyiyan, GLM, etc.
In order to explore the limits of performance, many researchers began to train increasingly larger language models, such as175B (1750 亿)parametricGPT-3and540B(5400 亿)parametricPaLM. Although these large language models differ from small language models (e.g.3.3 亿parametricBERTand15 亿parametricGPT-2) use similar architectures and pre-training tasks, but they exhibit completely different abilities, especially showing amazing potential in solving complex tasks, which is called "emergent ability". Taking GPT-3 and GPT-2 as examples, GPT-3 can solve few-shot tasks by learning context, while GPT-2 performs worse in this regard. Therefore, the scientific research community gave these huge language models a name, calling them "Large Language Models (LLM)". An outstanding application of LLM is ChatGPT, which is a bold attempt of the GPT series LLM for conversational applications with humans, showing very smooth and natural performance.
Research on language modeling can be traced back to20 世纪 90 年代, the research at that time mainly focused on using statistical learning methods to predict words, and predict the next word by analyzing the previous words. However, there are certain limitations in understanding complex language rules.
Subsequently, researchers continued to try to improve,2003 年Deep learning pioneer Bengio in his classic paper《A Neural Probabilistic Language Model》, the idea of deep learning was integrated into the language model for the first time. The powerful neural network model is equivalent to providing a powerful "brain" for the computer to understand language, allowing the model to better capture and understand the complex relationships in language.
2018 年Around this time, the Transformer architecture neural network model began to emerge. These models are trained through large amounts of text data, allowing them to deeply understand language rules and patterns by reading large amounts of text, just like letting computers read the entire Internet. They have a deeper understanding of language, which greatly improves the model's performance on various natural language processing tasks.
At the same time, researchers have found that as the scale of the language model increases (increasing the model size or using more data), the model exhibits some amazing capabilities, and its performance in various tasks is significantly improved (Scaling Law). This discovery marks the beginning of the era of large language models (LLMs).
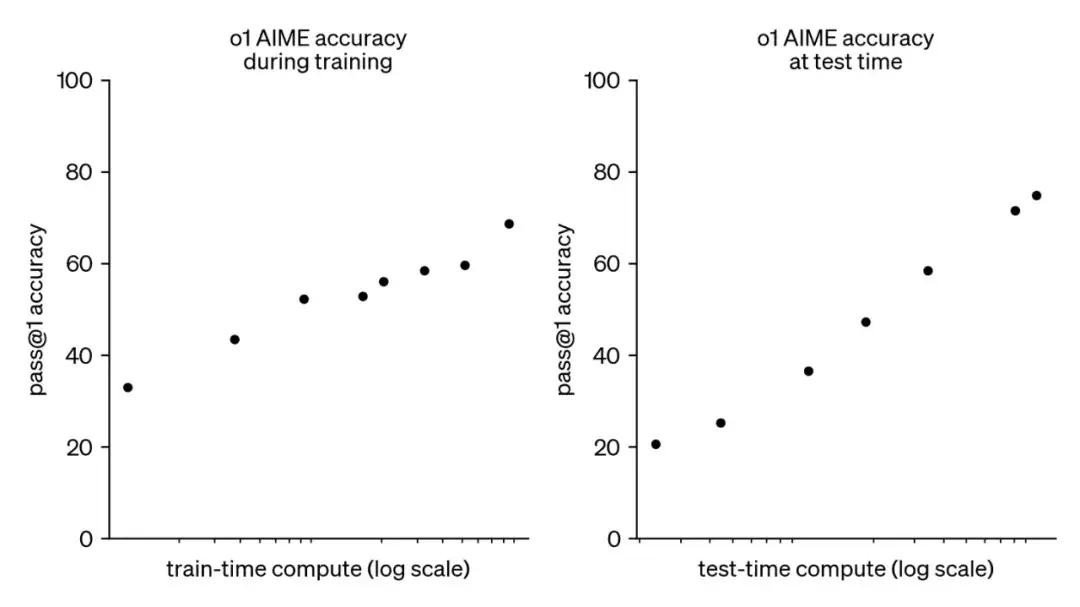
Usually large models consist of three stages: pre-training, post-training and online inference. Before September 2024, Scaling Law only exists in the pre-training stage in the field of large models. However, with the launch of OpenAI o1, the post-training and online reasoning phases also have their own Scaling Laws, namely reinforcement learning Scaling Law (RL Scaling Law) in the post-training phase and Inference Scaling Law (Test Time Scaling Law) in the online reasoning phase. As the amount of calculation at each stage increases, the performance of large models continues to grow.
1.1.1 Common LLM models
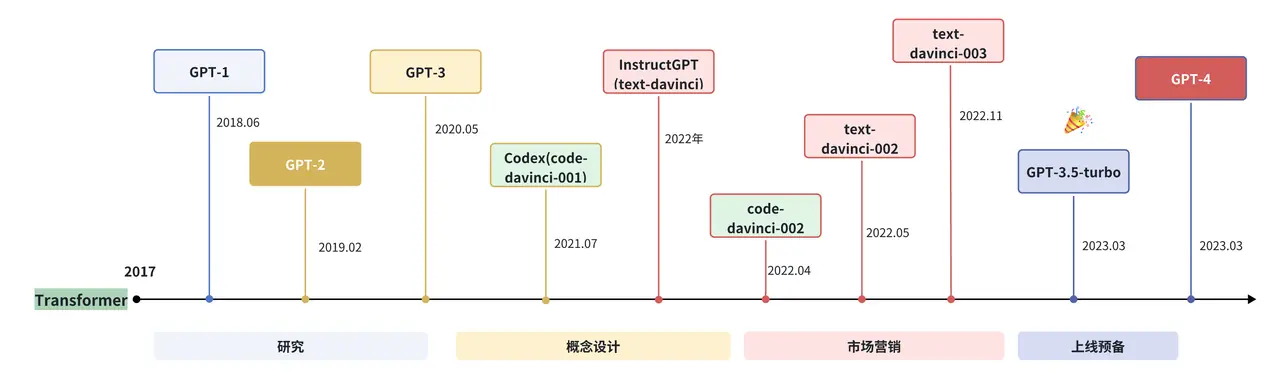
Although the development process of large language models has only lasted less than five years, the development speed is quite amazing. As of June 2024, more than a hundred large models have been released at home and abroad. The figure below shows the most influential large language models with more than 10 billion model parameters from 2019 to July 2024 according to the timeline:

(This picture comes from the reference content [1])
Next, we will mainly introduce several common large models at home and abroad (including open source and closed source)
OpenAI company in2018 年The proposed GPT (Generative Pre-Training) model is typical生成式预训练语言模型one.
The basic principle of the GPT model is to compress world knowledge into a decoder-only Transformer model through language modeling, so that it can recover (or remember) the semantics of world knowledge and act as a general task solver. Two key points for its success:
- Train a decoder-only Transformer language model that can accurately predict the next word
- Expanded language model size
OpenAI’s research on LLM can be roughly divided into the following stages:
Currently, the GPT/o series has formed an integrated evolution direction of universal generation + enhanced reasoning + Agent tool invocation.
2022 年 11 月, OpenAI released conversational application ChatGPT based on the GPT model (GPT-3.5 and GPT-4). ChatGPT has sparked excitement in the AI community since its release due to its exceptional ability to communicate with humans. ChatGPT is essentially an LLM application, which is developed based on the base model and is essentially different from the base model. After ChatGPT was launched, its users grew rapidly. The number of registered users exceeded 1 million within 5 days, and monthly active users exceeded 100 million two months later. It became the consumer application with the fastest user growth in history at that time.
With continuous iteration, ChatGPT gradually enriches its functions:
- Intelligent mode switching: The integrated system automatically switches intelligently between knowledge-based, reasoning-based and multi-modal modes without manual selection.
- Thinking chain: The system automatically determines when in-depth thinking is needed and can selectively display the reasoning process to help users understand the steps to solve complex problems.
- Cross-domain capabilities: Integrate coding, reasoning, and agent tasks into one, and solve all problems with one model
- Multi-modal capabilities: Ability to analyze and understand images, audio and videos provided by users to achieve comprehensive multi-modal interaction
- Real-time voice and video conversations: Users can have natural voice and video communication with AI, supporting gesture recognition and emotional expression
- Custom instructions and memory function: remember the user’s previous interaction habits and preferences to provide a personalized experience
- GPT builder platform: allows users to create dedicated AI assistants without programming, supporting custom knowledge bases and behavior patterns
- Data analysis and visualization: directly process and analyze uploaded data files, generate charts and visual reports
- Plug-in system: allows developers to create tools to extend the capabilities of ChatGPT to achieve web browsing, data analysis and third-party service calls
OpenAI model development history:
-
2023 年 3 月, released GPT-4, introducing multi-modal capabilities and significantly expanding the parameter scale. -
2024 年 5 月, released GPT-4o to achieve multi-modal fusion of text, voice, and images. -
2025 年 4 月, released the GPT-4.1 series and o3, o4-mini to strengthen long context capabilities and test-time reasoning (Test-Time Scaling). -
2025 年 8 月, released the open source models gpt-oss-120b and gpt-oss-20b to complete the ecological layout. -
2025 年 11 月Released GPT-5.1, OpenAI officially positions it as the latest flagship model, which is specially optimized for coding and agent tasks. It provides a context window of about 400k tokens and an output length of up to about 128k tokens. The knowledge deadline is September 30, 2024. It supports "inference tokens" andreasoning_effortParameters to configure inference intensity, outstanding performance in complex code generation and multi-step task orchestration. -
2025 年 12 月, released GPT-5.2, officially positioned as the best model for cross-industry coding and agent tasks. This model provides a context window of 400k tokens and a maximum output length of 128k tokens. Supports "Reasoning tokens", whichreasoning_effortThe parameters support configuration of five different inference strengths: none, low, medium, high and xhigh. -
2026 年 2 月, released GPT-5.3-Codex, integrating Codex and GPT-5 training stack to strengthen the general code Agent capabilities. GPT-5.3-Codex-Spark was released at the same time, which is designed for real-time programming and can achieve instant feedback of over a thousand Tokens. The ChatGPT Thinking mode context window is further extended to 256k tokens.
OpenAI’s current recommended main matrix:
OpenAI's model strategy has evolved from two complementary product lines, "knowledge-based" and "reasoning-based", to an integrated system: Traditionally, knowledge-based models focus on broad knowledge coverage and smooth conversational experience, while inference-based models focus on precise reasoning and complex problem solving. Through the integrated system, the organic integration of knowledge-based and reasoning-based capabilities is achieved. Users no longer need to manually switch models. The system will automatically select the most suitable processing method based on the complexity of the task.
The Claude series of models is a family of large closed-source models developed by Anthropic, a company founded by former OpenAI members. It is another mainstream route in the current closed-source camp alongside the GPT series.
- The earliest Claude was in
2023 年 3 月 15 日release. 2025 年 5 月, released Claude Opus 4 and Sonnet 4, introducing native code execution and extended thinking capabilities. Hybrid reasoning and stronger code/Agent capabilities are introduced for the first time. .2025 年 11 月, released Claude Opus 4.5, achieving cutting-edge performance in code, agents, and computer use.2026 年 2 月, released Claude Opus 4.6, which is officially positioned as the most powerful intelligent model currently, focusing on improving complex reasoning and long-term Agent coordination task capabilities. Claude Sonnet 4.6 was released at the same time, further improving the balance between speed and quality and Agent search performance.
Gemini series large language models are developed by Google.
2022 年 4 月, Google released PaLM (later renamed the Gemini series).2025 年 3 月, released Gemini 2.5 Pro (Thinking), incorporating controllable "thinking budget" into the model capability system.2025 年 12 月, released Gemini 3 Pro, which is positioned as a cutting-edge visual AI model, strengthening native multi-modal and spatial reasoning. At the same time, Gemini 3 Flash was released. As the most powerful model for processing agent workflows, it has 3 Pro-level reasoning capabilities, but has Flash-level extremely low latency and ultra-high cost performance. At the same time, the reasoning mode Gemini 3 Deep Think is launched, using iterative reasoning to solve complex problems.2026 年 2 月 19 日, released Gemini 3.1 Pro, as the latest flagship version, based on the hybrid expert (MoE) architecture, supporting 1 million contexts, making further breakthroughs in complex problem solving and advanced reasoning benchmarks, with scores exceeding GPT-5.2 and Claude 4.6.
The following window is the interface of Gemini:
Wenxinyiyan is a large knowledge-enhanced language model based on Baidu Wenxin large model.2023 年 3 月The first in the country to open an invitation test. Wenxin Yiyan's basic model Wenxin Large Model was released in version 1.0 in 2019.
2025 年 3 月, launched and open sourced Wenxin Large Model 4.5 Series, a multi-modal open source version containing 424 billion parameters, and announced that Wenxin Yiyan is completely free.2026 年 1 月 22 日, Baidu officially released the official version of Wenxin Large Model 5.0 (ERNIE 5.0), with a parameter scale of 2.4 trillion. It uses native full-modal unified modeling and ultra-large-scale hybrid expert structure (activation parameter ratio is less than 3%), surpassing many international advanced models in language and multi-modal understanding capabilities.
Further divided, Wenxin large models include NLP large models, CV large models, cross-modal large models, biological computing large models, and industry large models. Wen Xinyiyan's Chinese ability is relatively good.
At the same time, you can also use API to make calls (计费详情).
The following is the user interface of Wenxin (originally Wenxinyiyan):
iFlytek Spark Cognitive Large Model is a large language model released by iFlytek, which supports a variety of natural language processing tasks.
2023 年 5 月, released for the first time.2024 年 10 月, released model Spark 4.0 Turbo.2025 年 1 月, released Spark X1 (reasoning thinking model) and upgraded voice simultaneous interpretation capabilities.2025 年 11 月, released the deep inference large model ** Spark2026 年 2 月 11 日, officially released the Spark X2 large model, based on the national computing power training (293B MoE sparse architecture), the comprehensive reasoning performance is 50% higher than the previous generation, and it is comparable to the international best in mathematics, reasoning, language understanding and intelligent agent capabilities.
The following is the user interface of iFlytek Spark:
LLaMA series models are a set of large-scale and extremely successful basic language models open sourced by Meta, which have set a profound benchmark for the entire open source community ecosystem.
2023 年 2 月, released LLaMA.2023 年 7 月, released the LLaMA 2 model.2024 年 4 月, released the LLaMA 3 model.2024 年 7 月, released the LLaMA 3.1 model.2024 年 12 月, released the LLaMA 3.3 model (only the 70B instruction model is open source).2025 年 05 月, released the LLaMA 4 series of models.
They are both trained on trillions of characters, demonstrating how to train state-of-the-art models using only publicly available datasets, without relying on proprietary or inaccessible datasets. These datasets include Common Crawl, Wikipedia, OpenWebText2, RealNews, Books, and more. The LLaMA model uses large-scale data filtering and cleaning techniques to improve data quality and diversity and reduce noise and bias. The LLaMA model also uses efficient data parallel and pipeline parallel technologies to accelerate model training and expansion. The 405B parameter model is the first public open source model with a scale of hundreds of billions, and its performance benchmarks against commercial closed source models such as GPT-4o.
Like the GPT series, the LLaMA model also adopts a decoder-only architecture and combines some improvements from previous work. The LLaMA series is basically the benchmark for subsequent large models:
Pre-normalization 正则化: In order to improve training stability, LLaMA performs RMSNorm normalization on the input of each Transformer sub-layer. This normalization method can avoid the problem of gradient explosion and disappearance, and improve the convergence speed and performance of the model;SwiGLU 激活函数: Replace the ReLU nonlinearity with the SwiGLU activation function to increase the expressive ability and nonlinearity of the network while reducing the amount of parameters and calculations;旋转位置编码(RoPE,Rotary Position Embedding): The input of the model no longer uses position coding, but adds position coding at each layer of the network. RoPE position coding can effectively capture the relative position information in the input sequence and has better generalization capabilities.分组查询注意力(GQA,Grouped-Query Attention): By grouping queries and sharing keys and values within the group, the amount of calculation is reduced while maintaining model performance and improving the inference efficiency of large models.
LLaMA 4 Series for2025 年 4 月Released left and right is a new generation of open source multi-modal large models launched by Meta.
- Hybrid Expert Architecture (MoE): The main model adopts a large-scale hybrid expert structure, which significantly improves parameter scale and expression capabilities while ensuring inference speed and controllable deployment costs.
- Training data and multi-language capabilities: Compared with LLaMA 3, the magnitude of the pre-training corpus is improved by about an order of magnitude, covering 200+ languages. The performance on multi-language tasks is more balanced, and the ability in scenes other than English is significantly enhanced.
- Extra long context: The context window can reach approximately 10M tokens.
- Native multi-modal: Unify different modalities such as text, images, and videos into the same backbone model for pre-training, which significantly improves visual understanding, multi-modal retrieval, and generation tasks.
Scout 17B/109B and Maverick 17B/400B released by LLaMA 4 are available in basic version (Base) and instruction fine-tuned version (Instruct).
DeepSeek is a series of open source large language models developed by the DeepSeek team. First version in2023 年 11 月release. DeepSeek adopts a decoder-only architecture, integrates advanced technologies such as FlashAttention, RoPE, and SwiGLU, and performs well in multi-language understanding and code generation.
Model development history:
2023 年 11 月 12 日: Release the DeepSeek series basic models, including Base and Chat versions in two sizes: 7B and 67B. The model was trained on 1.2 trillion tokens, and the DeepSeek-Coder dedicated code generation model was released.2024 年: DeepSeek-V2 series, DeepSeek-V2.5, DeepSeek-MoE hybrid expert models will be released one after another.2024 年 10 月: Released DeepSeek-V3, which has significantly improved reasoning capabilities, multi-language understanding and creative generation, supports more complex system prompt word control, and further improved code quality and multi-round dialogue consistency.2025 年 2 月:- DeepSeekR1 Inferential large model, focusing on complex problem solving and precise reasoning capabilities, showing excellent performance in mathematics, logical reasoning and structured knowledge, similar to OpenAI's o1 series. And it is the first open source inference large model**, surpassing the o1 series in multiple benchmark tests.
- DeepSeek-R1-Zero Models trained directly in large-scale reinforcement learning (RL), without the need for SFT, excel at inference.
- At the same time, six dense models distilled from DeepSeek-R1 using Llama and Qwen are open sourced. Among them, DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini in various benchmark tests.
2025 年 8 月: Released the hybrid inference model DeepSeek-V3.1, which improves inference efficiency while reducing token consumption, optimizing tool invocation and agent collaboration capabilities, and enhancing information retrieval performance through dedicated search tokens.2025 年 10 月: Released the DeepSeek-OCR model, which implements long document OCR and high compression ratio text encoding through optical 2D mapping and other technologies, significantly reducing context token consumption while maintaining recognition accuracy, and providing basic capabilities for long text retrieval and "external memory" scenarios.2025 年 12 月: Released DeepSeek-V3.2, which further introduces DeepSeek Sparse Attention (DSA) and other technologies on the basis of V3/V3.1, which significantly improves training and inference efficiency in long context scenarios, and further enhances the ability to control prompt words in complex systems.
The main improvements DeepSeek currently employs are as follows:
- Multi-head Latent Attention (MLA): By significantly compressing the key-value (KV) cache into latent vectors, it ensures efficient inference without reducing the effect.
- DeepSeekMoE, train powerful models affordably through sparse computation.
- DeepSeek Sparse Attention (DSA, DeepSeek Sparse Attention): It implements learnable sparse attention connections through lightning indexers and token selectors, significantly reducing attention calculation overhead under long contexts.
- A series of inference acceleration technologies
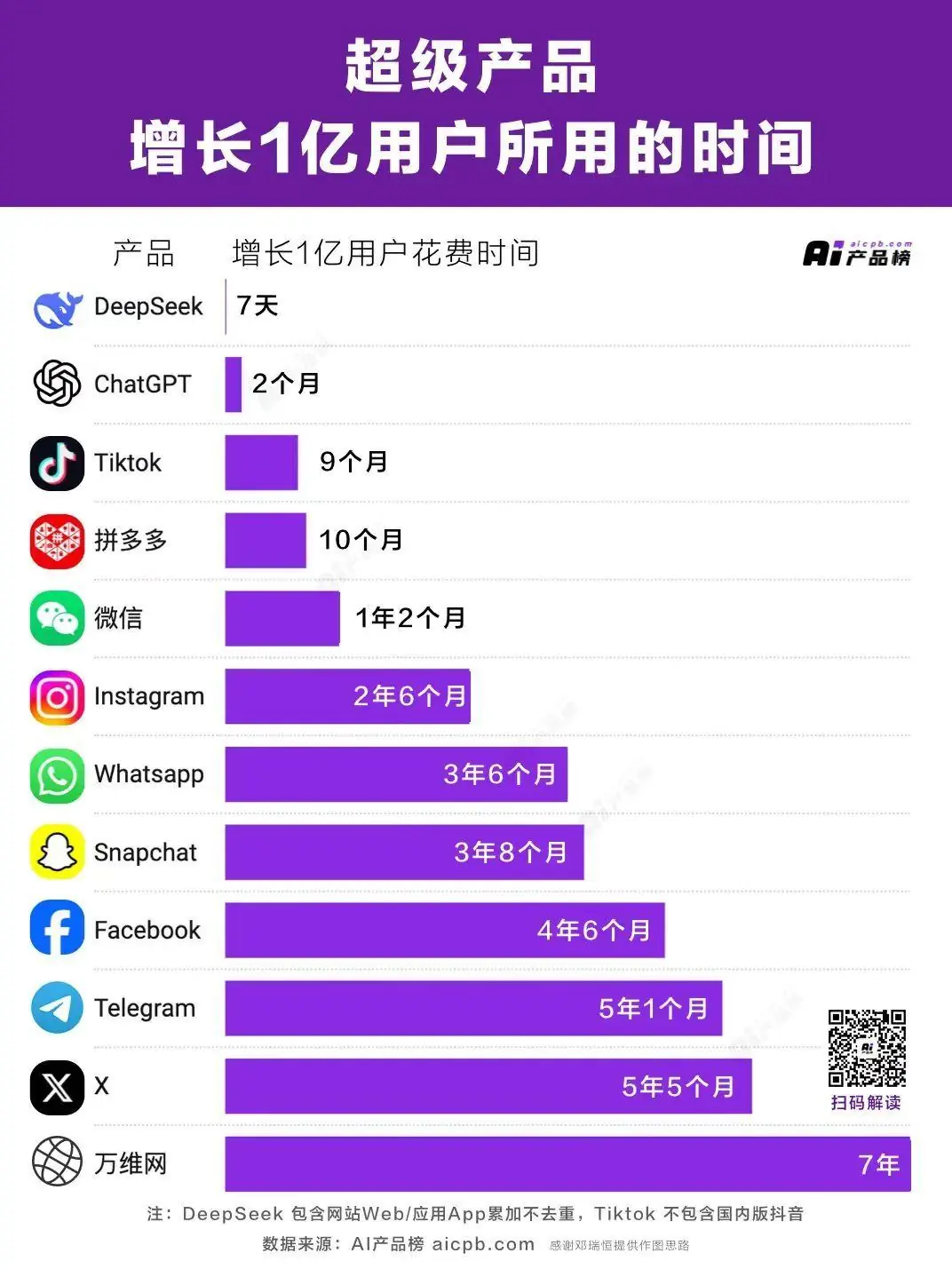
With the outstanding capabilities of DeepSeek-R1, DeepSeek has become a phenomenon-level explosive application. It completed the growth of 100 million users in 7 days, breaking the fastest record of ChatGPT reaching this scale in about 2 months, and becoming the fastest growing AI application in history.
The following is the interface of DeepSeek:
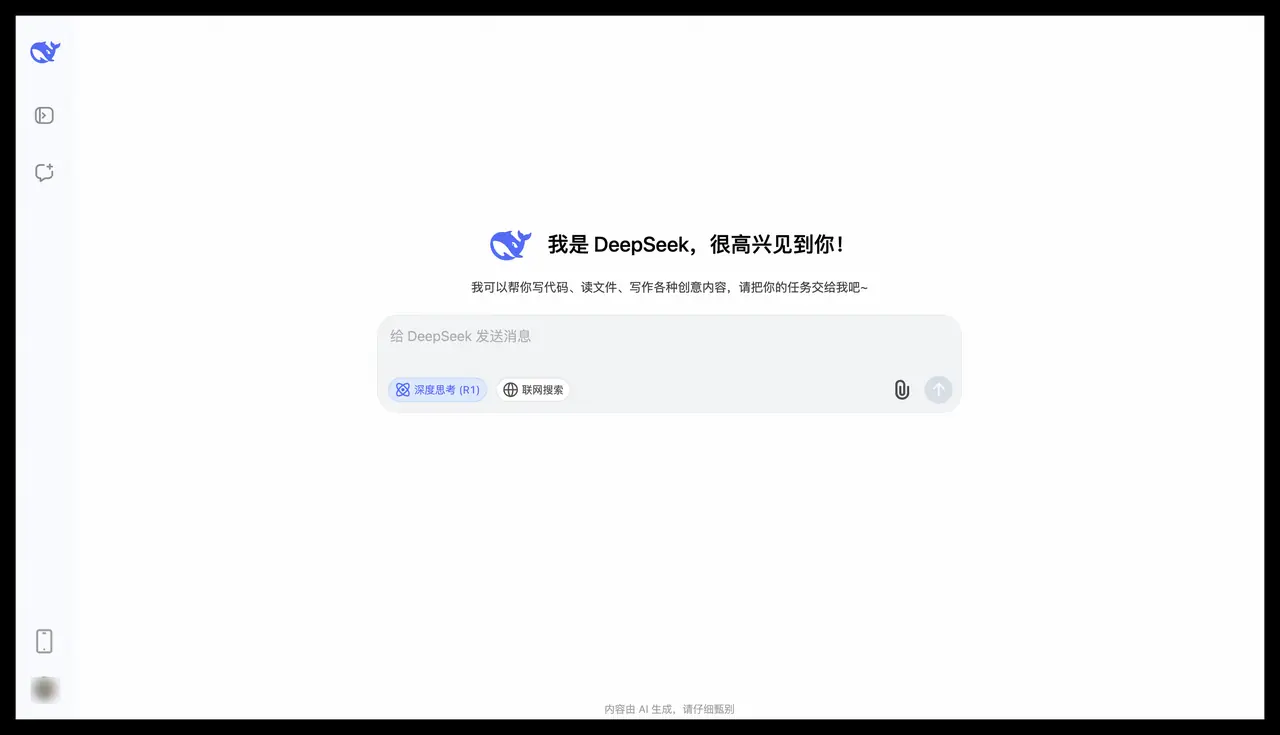
At present, all major mainstream platforms have basically accessed DeepSeek.
Tongyi Qianwen was developed by Alibaba based on the "Tongyi" large model.2023 年 4 月Officially released.
The Qwen series all adopt the decoder-Only architecture and combineSwiGLU 激活、RoPE、GQAand other technologies. It is an open source model that has relatively good Chinese proficiency.
2023 年 9 月, Alibaba Cloud open sourced the Qwen (Tongyi Qianwen) series of work.2024 年 6 月, officially open sourced Qwen2.2025 年上半年, released the Qwen3 series and Qwen3 Embedding, introducing hybrid reasoning mode and enhanced retrieval.2026 年 2 月, released a new generation of multi-modal model Qwen 3.5. The first version is a 397B parameter (17B activation parameter) MoE model, combined with a gated delta network to achieve low-cost and high-throughput inference. Through multi-modal early fusion training and reinforcement learning in a million-level agent environment, it comprehensively surpasses the previous generation in reasoning, programming, agent and visual understanding, and expands to support up to 201 languages.
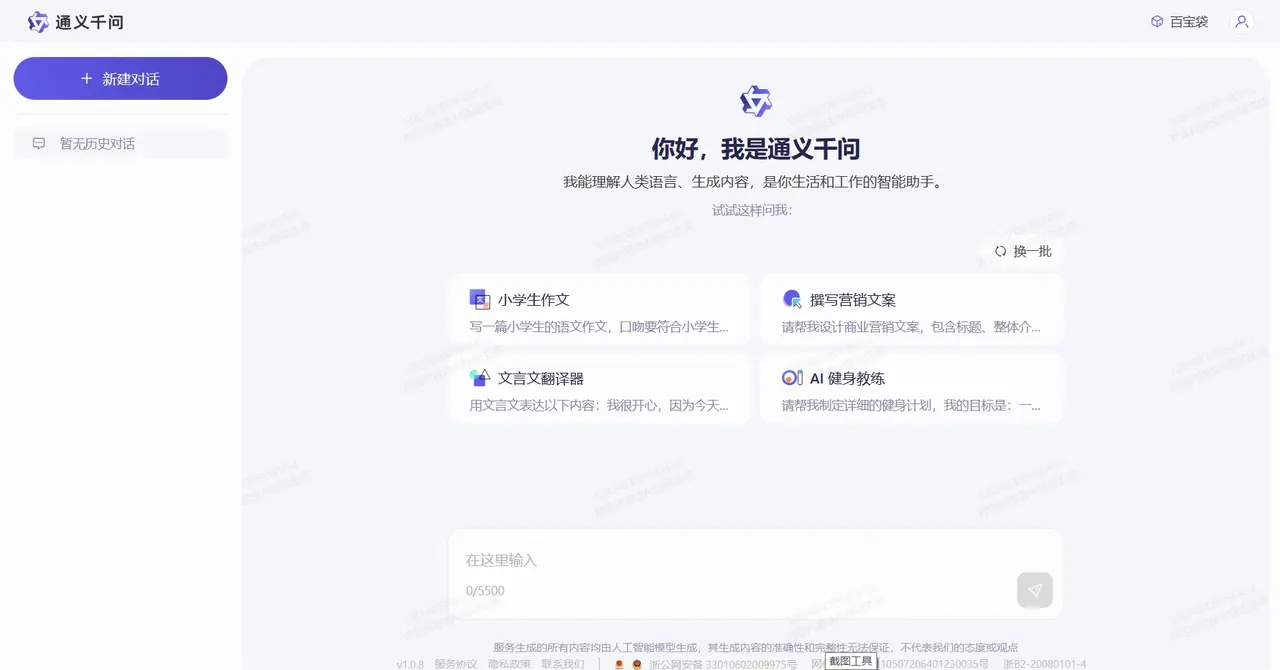
The following is the user interface of Tongyi Qianwen:
GLM series model is a general-purpose large language model jointly developed by **Tsinghua University and Zhipu AI.
2023 年 3 月, released ChatGLM.2026 年 2 月, Zhipu officially released the new generation flagship model GLM-5. It is oriented to complex system engineering and long-term tasks. The parameter size is expanded to 744B (40B activation parameters), and the pre-training data reaches 28.5T tokens. This model integrates DeepSeek Sparse Attention (DSA) to significantly reduce the deployment cost of long contexts and is the first toslimeAsynchronous reinforcement learning infrastructure to improve training efficiency. GLM-5 has reached the top level of global open source models in tasks such as reasoning, programming, and agents.
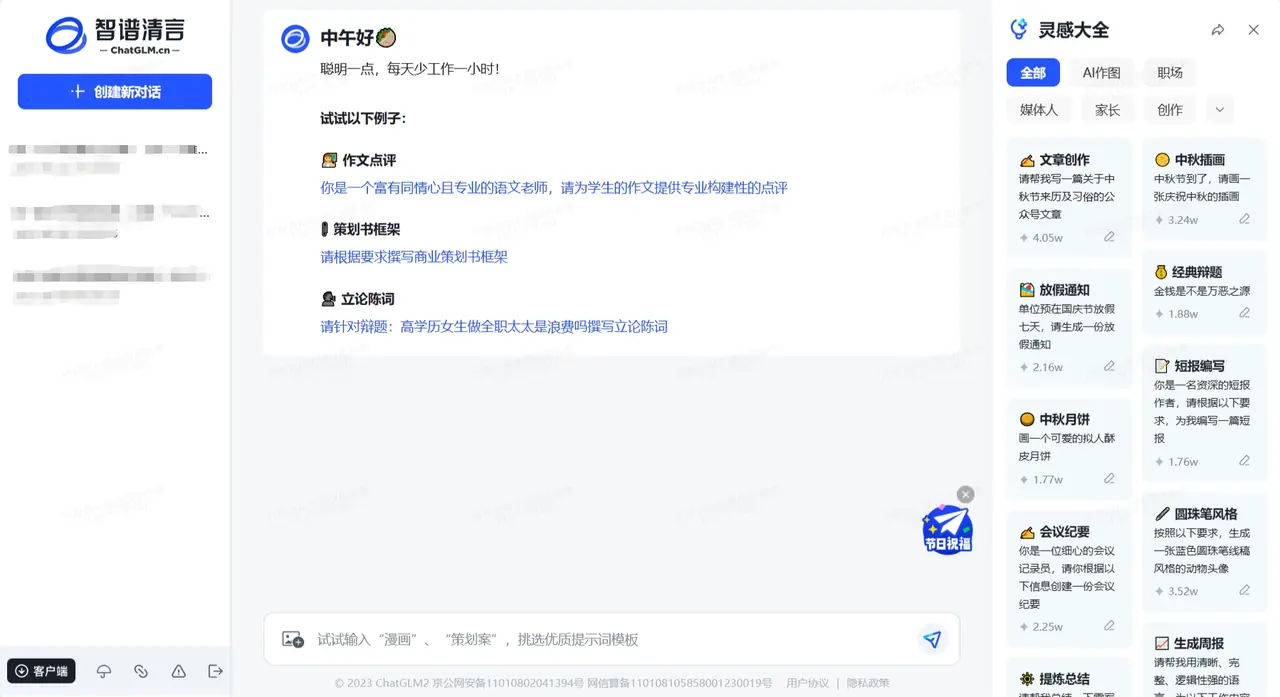
The following is the user interface of Zhipu Qingyan:
Baichuan is an open source and commercially available large language model developed by Baichuan Intelligence. It is based on the Transformer decoder architecture (decoder-only).
2023 年 6 月, released Baichuan-7B and Baichuan-13B.- Baichuan2 at
2023 年 9 月roll out. 2024 年 1 月, released Baichuan 3.2024 年 5 月, released Baichuan 4, and simultaneously launched the AI assistant "Baixiaoying" to realize multiple rounds of search and speed reading of long documents.2025 年 1 月, released the deep thinking model Baichuan-M1-preview.2025 年 10 月, released the evidence-based enhanced medical model Baichuan-M2 Plus.2026 年 1 月, officially released the new generation model Baichuan-M3 Plus. Integrating professional medical literature, the performance reaches extremely high levels in core medical diagnosis and complex reasoning assessment.
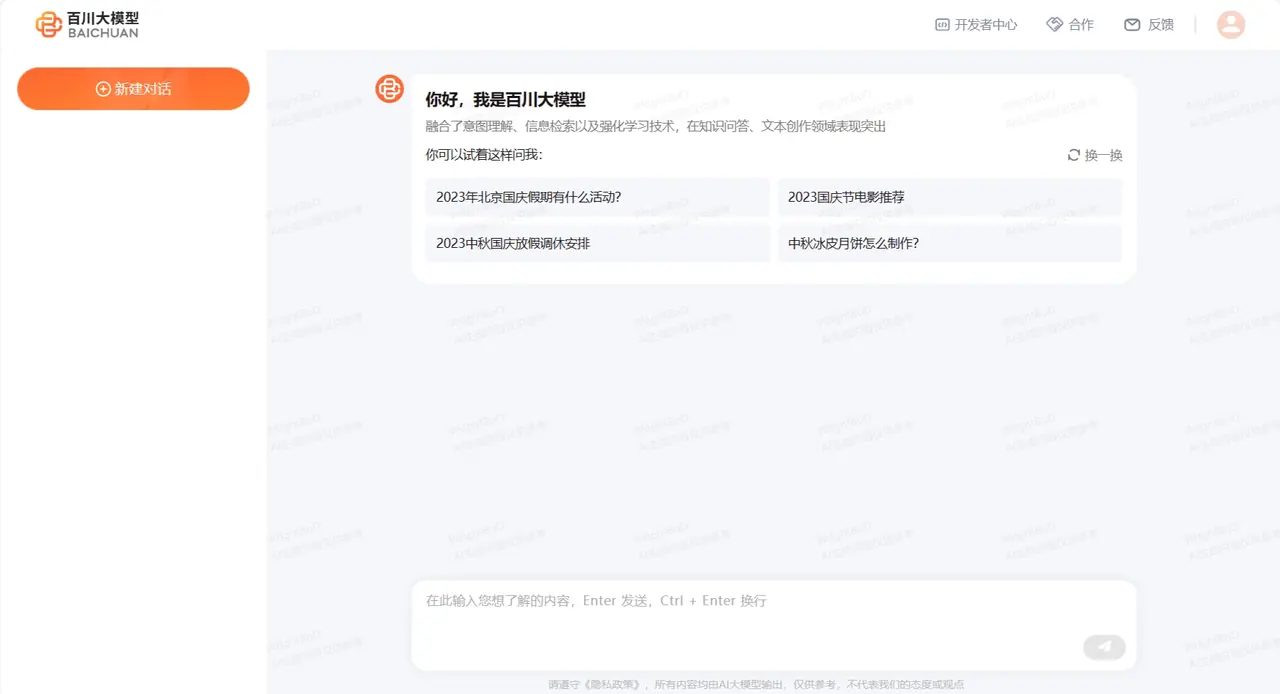
The following is the user interface of the Baichuan large model:
1.1.2 Characteristics and capabilities of LLM
Large language models have several distinctive characteristics that make them arouse widespread interest and research in natural language processing and other fields. Here are some key features of large language models:
-
Huge scale: LLMs often have huge parameter scales, reaching billions or even hundreds of billions of parameters. This allows them to capture more language knowledge and complex grammatical structures.
-
Pre-training and fine-tuning: LLM adopts the learning method of pre-training and fine-tuning. First, pre-train on large-scale text data (unlabeled data) to learn universal language representation and knowledge. It is then adapted to the specific task through fine-tuning (with labeled data) to perform well in a variety of NLP tasks.
-
Context awareness: LLM has strong context awareness when processing text, and can understand and generate text content that depends on the previous text. This makes them great at conversation, article generation, and situational understanding.
-
Multi-language support: LLM can be used in multiple languages, not just English. Their multilingual capabilities make cross-cultural and cross-language applications easier.
-
Multimodal support: Some LLMs have been extended to support multimodal data, including text, images, and sounds. This enables them to understand and generate content of different media types and achieve more diverse applications.
-
Ethical and Risk Issues: Despite their excellent capabilities, LLMs also raise ethical and risk issues, including the generation of harmful content, privacy concerns, cognitive biases, and more. Therefore, studying and applying LLM requires caution.
-
High computing resource requirements: LLM parameters are large in size and require a large amount of computing resources for training and inference. This usually requires the use of high-performance GPU or TPU clusters.
Large language models are a technology with powerful language processing capabilities that have demonstrated potential in multiple fields. They provide powerful tools for natural language understanding and generation tasks, while also raising concerns about their ethics and risks. These characteristics make LLM an important research and application direction in today's computer science and artificial intelligence fields.
1.1.2.1 Emergent abilities
One of the most notable features that distinguish large language models (LLMs) from previously pretrained language models (PLMs) is their涌现能力. Emergent capability is a surprising ability that is not apparent in small models but is particularly prominent in large models. Similar to the phase change phenomenon in physics, emergence capability is like a model performance that rapidly improves as the scale increases, exceeding the random level. This is what we often call quantitative changes causing qualitative changes.
Emergent abilities can be related to certain complex tasks, but we are more concerned with their general abilities. Next, we briefly introduce three typical emergent capabilities of LLM:
-
Context Learning: Context learning capability was first introduced by GPT-3. This capability allows language models, given natural language instructions or multiple task examples, to perform tasks by understanding the context and generating appropriate output without the need for additional training or parameter updates.
-
Command following: Fine-tuning by using multi-task data described in natural language, also known as
指令微调. LLM is shown to perform well on unseen tasks formally described using instructions. This means that LLM is able to perform tasks based on task instructions without having to see specific examples beforehand, demonstrating its strong generalization capabilities. -
Step-by-step reasoning: Small language models often struggle to solve complex tasks involving multiple reasoning steps, such as mathematical problems. However, LLM adopts
思维链(CoT, Chain of Thought)Reasoning strategies that solve these tasks using prompting mechanisms involving intermediate reasoning steps to arrive at the final answer. Presumably, this ability may be acquired through training in the code.
These emergent capabilities allow LLMs to perform well in a variety of tasks, making them powerful tools for solving complex problems and having applications in multiple domains.
1.1.2.2 The ability to support multiple applications as a base model
In 2021, researchers from Stanford University and other universities proposed the concept of foundation model, clarifying the role of pre-training models. This is a new AI technology paradigm that relies on the training of massive unlabeled data to obtain large models (single-modal or multi-modal) that can be applied to a large number of downstream tasks. In this way, multiple applications can be constructed uniformly relying on only one or a few large models.
Large language models are a typical example of this new model. Using unified large models can greatly improve R&D efficiency. This is a substantial improvement over developing a single model at a time. Large models can not only shorten the development cycle of each specific application and reduce the required manpower investment, but also achieve better application results based on the reasoning, common sense and writing skills of large models. Therefore, the large model can become a unified base model for AI application development. This is a new paradigm that serves multiple purposes and deserves to be vigorously promoted.
1.1.2.3 The ability to support dialogue as a unified entrance
The opportunity that makes big language models really popular is ChatGPT based on conversational chat. The industry has long discovered users' special preference for conversational interaction. During Lu Qi's time at Microsoft, he promoted the "conversation as a platform" strategy in 2016. In addition, voice conversation-based products such as Apple’s Siri and Amazon Echo are also very popular, reflecting Internet users’ preference for interaction modes such as chat and conversation. Although previous chatbots had various problems, the emergence of large-scale language models has once again allowed the interaction model of chatbots to re-emerge. Users are increasingly looking forward to artificial intelligence like "Jarvis" in Iron Man, omnipotent and omniscient. This leads us to智能体(Agent)Thinking about the prospects of type applications, projects such as Auto-GPT and Microsoft Jarvis have emerged and attracted attention. I believe that many similar projects will emerge in the future that allow assistants to complete various specific tasks in the form of conversations.
LLM has had a profound impact in many fields. In the field of natural language processing, it can help computers better understand and generate text, including writing articles, answering questions, translating languages, etc. In the field of information retrieval, it can improve search engines and make it easier for us to find the information we need. In the field of computer vision, researchers are also working to make computers understand images and text to improve multimedia interactions.
Most importantly, the emergence of LLM has made people rethink the possibility of Artificial General Intelligence (AGI). AGI is artificial intelligence that thinks and learns like humans. LLM is considered an early form of AGI, which has led to many thoughts and plans for future artificial intelligence developments.
In short, LLM is an exciting technology that allows computers to better understand and use language. It is changing the way we interact with technology, and it also triggers endless exploration of future artificial intelligence.
In the next chapter we will introduce an important technical RAG during the LLM period.
[Reference content]:
- A Survey of Large Language Models
- A Survey of Large Language Models
- 周枫:当我们谈论大模型时,应该关注哪些新能力?
- S 型智能增长曲线:从 Deepseek R1 看 Scaling Law 的未来
- 一文详尽之 Scaling Law!
- QwQ: 思忖未知之界
- QwQ-32B: 领略强化学习之力
1.2 What is RAG
Large language models (LLMs) are more powerful than traditional language models, however, they may still not provide accurate answers in some cases. In order to solve a series of challenges faced by large language models when generating text and improve the performance and output quality of the model, researchers proposed a new model architecture: Retrieval-Augmented Generation (RAG, Retrieval-Augmented Generation). This architecture cleverly integrates relevant information retrieved from a huge knowledge base, and based on this, guides large-scale language models to generate more accurate answers, thus significantly improving the accuracy and depth of answers.
The main problems currently faced by LLM are:
-
Information Bias/Illusion: LLM sometimes produces information that is inconsistent with objective facts, resulting in inaccurate information received by users. RAG assists the model generation process by retrieving data sources to ensure the accuracy and credibility of the output content and reduce information bias.
-
Knowledge update lag: LLM is based on static data set training, which may cause the model's knowledge update to lag and fail to reflect the latest information trends in a timely manner. RAG keeps content current by retrieving the latest data in real-time, ensuring continuous updates and accuracy of information.
-
Content is not traceable: The content generated by LLM often lacks clear sources of information, affecting the credibility of the content. RAG links the generated content with the retrieved original materials, enhancing the traceability of the content and thereby increasing users' trust in the generated content.
-
Lack of domain expertise: LLM may not be as effective when dealing with expertise in a specific field, which may affect the quality of its answers in related fields. RAG provides the model with rich contextual information by retrieving relevant documents in a specific field, thereby improving the quality and depth of answer questions in professional fields.
-
Reasoning ability limitation: When faced with complex problems, LLM may lack the necessary reasoning ability, which affects its understanding and answer to the question. RAG combines the retrieved information with the model's generative capabilities, enhancing the model's reasoning and understanding capabilities by providing additional background knowledge and data support.
-
Limited adaptability to application scenarios: LLM needs to remain efficient and accurate in diverse application scenarios, but a single model may not be able to fully adapt to all scenarios. RAG enables LLM to flexibly adapt to various application scenarios such as question and answer systems and recommendation systems by retrieving corresponding application scenario data.
-
Weak ability to process long text: LLM is limited by a limited context window when understanding and generating long content, and must process content sequentially. The longer the input, the slower it becomes. RAG strengthens the model's understanding and generation of long context by retrieving and integrating long text information, effectively breaking through the limit of input length, reducing call costs, and improving overall processing efficiency.
1.2.1 RAG workflow
RAG is a complete system, and its workflow can be simply divided into four stages: data processing, retrieval, enhancement and generation:

- Data processing stage
- Clean and process the original data.
- Convert the processed data into a format that can be used by the retrieval model.
- Store the processed data in the corresponding database.
- Retrieval Phase
- Input the user's questions into the retrieval system and retrieve relevant information from the database.
- Enhancement Phase
- Process and enhance the retrieved information so that the resulting model can be better understood and used.
- Generation Phase
- Input the enhanced information into the generative model, which generates answers based on this information.
1.2.2 RAG VS Finetune
In improving the effect of large language models, RAG and Finetune are two mainstream methods.
Fine-tuning: Improve the performance of the model on specific tasks by further training the large language model on a specific data set.
For comparison between RAG and fine-tuning, please refer to the table below (table source[1][2])
1.2.3 Success Stories of RAG
RAG has achieved success in multiple fields, including question and answer systems, dialogue systems, document summarization, document generation, etc.
We will introduce the application of RAG in detail in the third part. Dismantle the existing mature RAG cases and learn more about RAG with everyone.
- Datawhale 知识库助手 is an LLM application that combines the content of this course and builds on ChatWithDatawhale - the Datawhale content learning assistant built by 散步. It adjusts the architecture to the LangChain architecture that is easy for beginners to learn, and encapsulates the APIs of large models from different sources with reference to Chapter 2. It can help users communicate smoothly with DataWhale's existing warehouses and learning content, thereby helping users quickly find the content they want to learn and the content they can contribute.
- 天机 is a free, non-commercial artificial intelligence system produced by SocialAI (Laishier AI). You can use it to perform tasks involving traditional human relations, such as how to toast, how to say nice things, how to make trouble, etc., to improve your emotional intelligence and core competitiveness. We firmly believe that only human sophistication is the core technology of future AI. Only AI that can do things will have a chance to move towards AGI. Let us join hands to witness the advent of general artificial intelligence. —— "The secret must not be leaked."
In this chapter we have a brief understanding of RAG. In the next chapter we will introduce LangChain, a commonly used RAG development framework.
[Reference content]:
- Retrieval-Augmented Generation for Large Language Models: A Survey
- Retrieval enhancement generation technology for large language models: a review [Translation]
1.3 LangChain
The great success of ChatGPT has stimulated the interest of more and more developers, who hope to use the APIs or private models provided by OpenAI to develop applications based on large language models. Although invoking large language models is relatively simple, creating a complete application still requires a lot of custom development work, including API integration, interaction logic, data storage, and more.
In order to solve this problem, starting in 2022, many institutions and individuals have launched multiple open source projects, aiming to help developers quickly build end-to-end applications or workflows based on large language models. One of the projects that is getting a lot of attention is the LangChain framework.
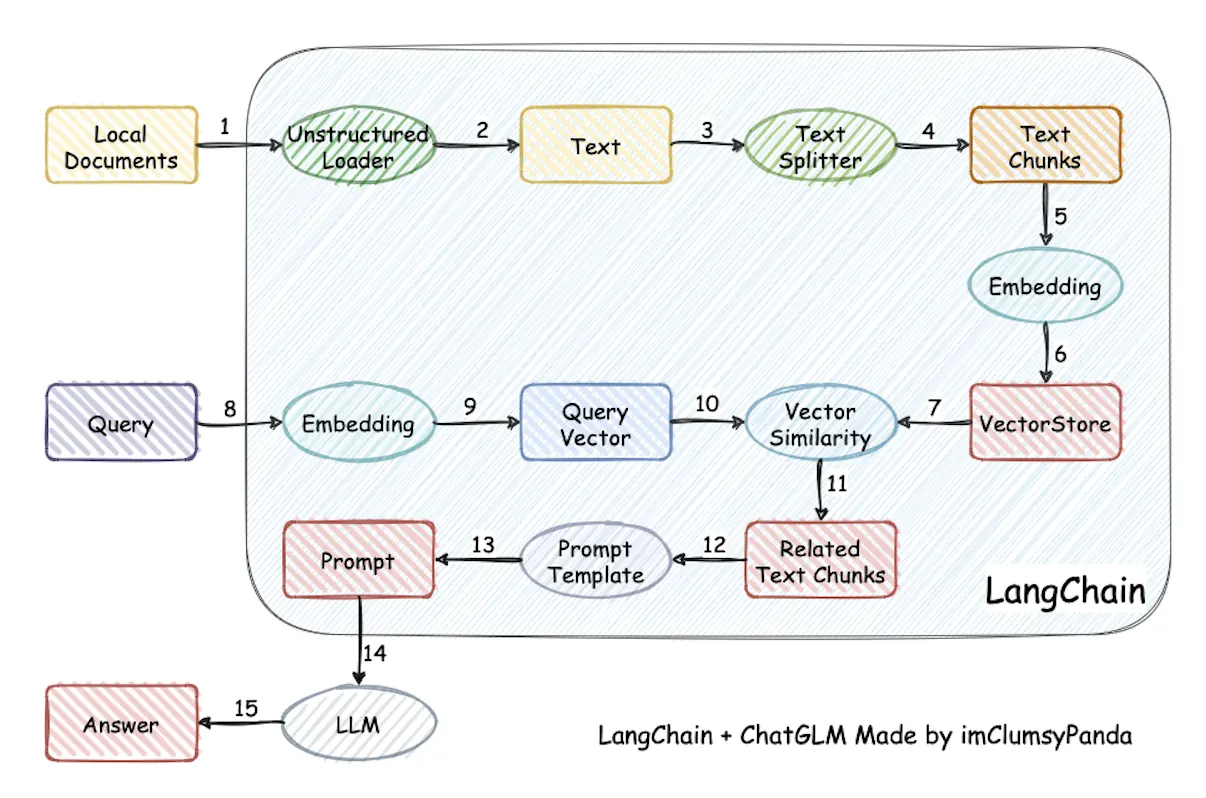
The LangChain framework is an open source tool that leverages the power of large language models to develop a variety of downstream applications. Its goal is to provide a common interface for various large-scale language model applications, thereby simplifying the application development process. Specifically, the LangChain framework enables data awareness and environment interaction, that is, it enables language models to connect to other data sources and allows language models to interact with their environment.
Using the LangChain framework, we can easily build a RAG application as shown below (图片来源). In the picture below,每个椭圆形代表了 LangChain 的一个模块, such as data collection module or preprocessing module.每个矩形代表了一个数据状态, such as raw data or preprocessed data. Arrows indicate the direction of data flow, from one module to another. At every step, LangChain can provide corresponding solutions to help us handle various tasks.
1.3.1 Core components of LangChain
As a large language model development framework, LangChian can integrate LLM models (dialogue models, embedding models, etc.), vector databases, interaction layer prompts, external knowledge, and external agent tools, so that you can freely build LLM applications. LangChain mainly consists of the following 6 core components:
- Model I/O: Interface for interacting with the language model
- Data connection: An interface for interacting with data from a specific application
- Chains: Combining components to achieve end-to-end applications. For example, in the future we will build
检索问答链to complete the search Q&A. - Memory: used to persist application state between multiple runs of the chain;
- Agents: Expand the reasoning capabilities of the model. Call sequences for complex applications;
- Callbacks: Expand the model's reasoning capabilities. Call sequences for complex applications;
During the development process, we can flexibly combine according to our own needs.
1.3.2 Stable version of LangChain
In the rapid development wave of LLM technology, LangChain, as an evolving innovation platform, continues to promote the expansion of technological boundaries.2024 年 9 月 16 日, LangChain officially released its stable version v0.3. This milestone update brings comprehensive and powerful functional support to developers. It covers key components such as model input and output processing, data connection, chain operations, memory mechanism, agent services, and callback processing, providing a solid foundation for the development and deployment of LLM applications.
At the same time, LangChain’s continuous optimization and function iteration will bring more innovative features and performance improvements in the future.
-
Compatibility and Support: LangChain takes care of both
Python 和 JavaScriptsupport while maintaining backward compatibility, ensuring that developers can seamlessly transition during the upgrade process and enjoy a more secure and stable development experience. -
Architecture improvements: By effectively separating the core component langchain-core from the partner package, LangChain's architectural design becomes more organized and stable, laying a solid foundation for future systematic expansion and security improvements.
-
Observability: LangChain provides industry-leading debugging and observability capabilities through deep integration with LangSmith. This allows developers to have a clear understanding of each operation in the LLM application and its input and output, greatly simplifying the debugging and troubleshooting process.
-
Extensive integrations: LangChain has nearly 700 integrations, covering multiple technology areas from LLM to vector storage, tools and agents, greatly reducing the complexity of building LLM applications on various technology stacks.
-
Composability: with the help of
LangChain 表达式语言(LCEL), developers can easily build and customize chains, taking full advantage of the data orchestration framework, including advanced features such as batch processing, parallel operations, and alternatives. -
Streaming processing: LangChain has deeply optimized streaming processing to ensure that all chains created using LCEL can support streaming processing, including data streaming in intermediate steps, thereby providing users with a smoother experience.
-
Output Parsing: LangChain provides a series of powerful output parsing tools to ensure that LLM can return information in a structured format, which is crucial for LLM to execute specific action plans.
-
Retrieval capabilities: LangChain introduces advanced retrieval technology suitable for production environments, including text segmentation, retrieval mechanisms, and indexing pipelines, allowing developers to easily combine private data with LLM capabilities.
-
Tool usage and agents: LangChain provides a rich collection of agents and tools, and provides an easy way to define tools to support agent workloads, including letting LLM call functions or tools, and how to efficiently perform multiple calls and reasoning, which greatly improves development efficiency and application performance.
1.3.3 Ecology of LangChain
-
LangChain Community: Focusing on third-party integration has greatly enriched the LangChain ecosystem, making it easier for developers to build complex and powerful applications, while also promoting community cooperation and sharing.
-
LangChain Core: The core library and core components of the LangChain framework, providing basic abstractions and LangChain Expression Language (LCEL), providing infrastructure and tools for building, running and interacting with LLM applications, providing a solid foundation for the development of LangChain applications. The document processing, prompt formatting, output parsing, etc. that we will use later all come from this library.
-
LangChain CLI: A command line tool that enables developers to interact with the LangChain framework through the terminal and perform tasks such as project initialization, testing, and deployment. Improve development efficiency and allow developers to manage the entire application life cycle through simple commands.
-
LangServe: Deployment service for deploying LangChain applications to the cloud, providing a scalable, highly available hosting solution with monitoring and logging capabilities. Simplifying the deployment process allows developers to focus on application development without having to worry about the underlying infrastructure and operation and maintenance work.
-
LangSmith: Developer platform, focusing on the development and debugging-testing of LangChain applications, providing visual interfaces and performance analysis tools, aiming to help developers improve the quality of applications and ensure that they meet expected performance and stability standards before deployment.
In this chapter we briefly introduce the development framework LangChain, and in the next chapter we will introduce the overall process of developing LLM applications.
1.4 Large model development
We will develop applications that take large language models as the core of functions, use the powerful understanding and generation capabilities of large language models, and combine special data or business logic to provide unique functions as large model development. Although the core technical focus of developing large model-related applications is large language models, core understanding and generation are generally achieved by calling APIs or open source models, and control of large language models is achieved through Prompt Enginnering. Therefore, although large models are a masterpiece in the field of deep learning, large model development is more of an engineering problem.
In the development of large models, we generally do not significantly change the model. Instead, we use the large model as a calling tool and use prompt engineering, data engineering, business logic decomposition and other means to fully utilize the capabilities of the large model and adapt to the application tasks, instead of focusing on optimizing the model itself. Therefore, as beginners in large model development, we do not need to study the internal principles of large models in depth, but more need to master the practical skills of using large models.
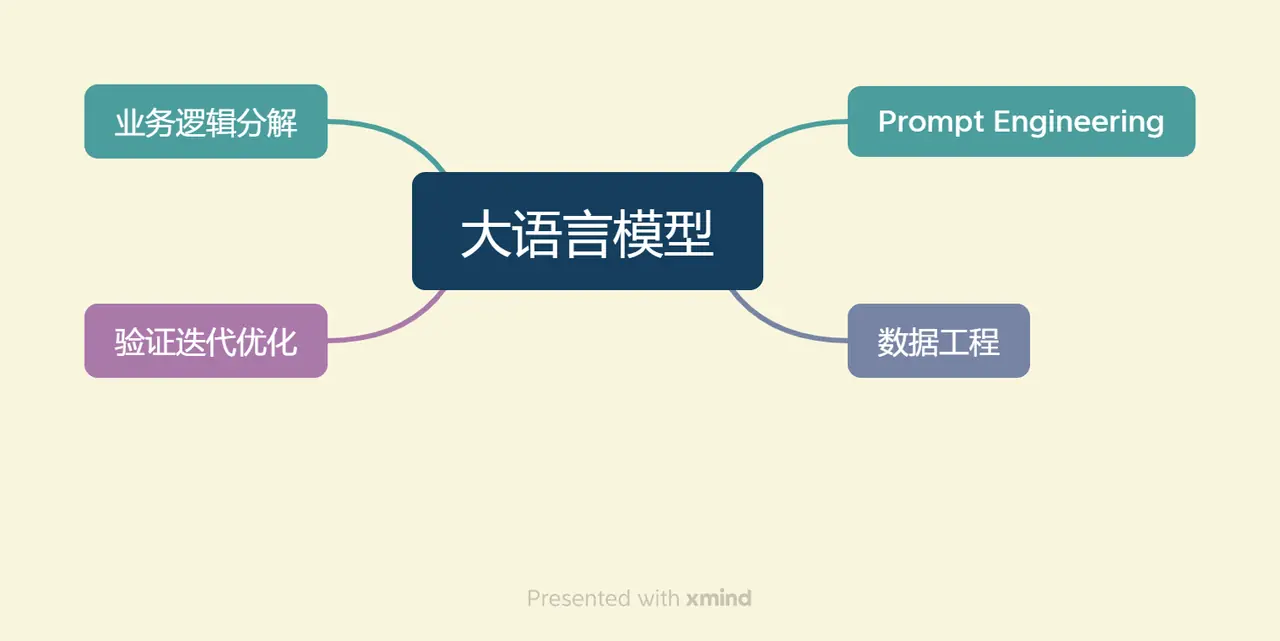
At the same time, large model development that focuses on calling and utilizing large models is quite different from traditional AI development in terms of overall ideas. Two core capabilities of large language models:指令遵循and文本生成Provides a simple alternative to complex business logic.
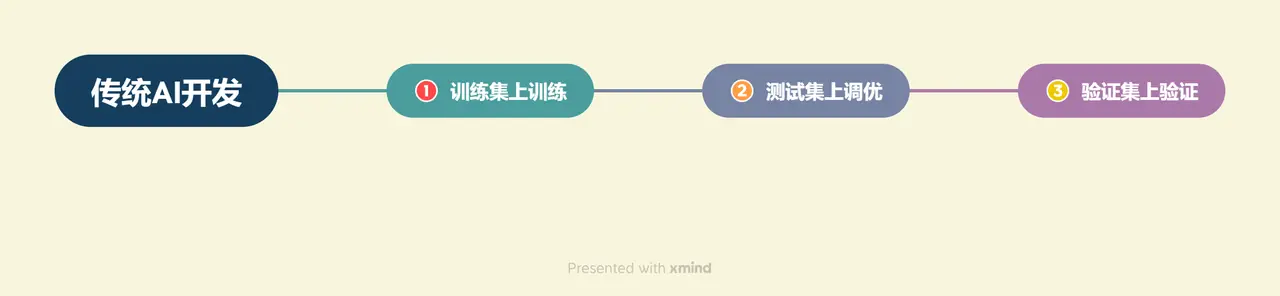
传统的 AI 开发: First, the very complex business logic needs to be disassembled in sequence, training data and verification data are constructed for each sub-business, and optimization models are trained for each sub-business, and finally a complete model link is formed to solve the entire business logic.大模型开发: Use Prompt Engineering to replace the training and tuning of sub-models, implement business logic through Prompt link combinations, and use a general large model + several business Prompts to solve tasks, thereby transforming traditional model training and tuning into simpler, easier, and lower-cost Prompt design and tuning.
At the same time, there are also qualitative differences between large model development and traditional AI development in terms of evaluation ideas.
传统 AI 开发: You need to first construct a training set, a test set, and a validation set, and then evaluate the performance by training the model on the training set, tuning the model on the test set, and finally verifying the model effect on the validation set.大模型开发: Processes are more flexible and agile. Construct a small batch verification set based on actual business needs, and design reasonable prompts to meet the verification set effect. Then, the Bad Case of the current Prompt will be continuously collected from the business logic, and the Bad Case will be added to the verification set to optimize the Prompt in a targeted manner, and finally achieve better generalization effects.
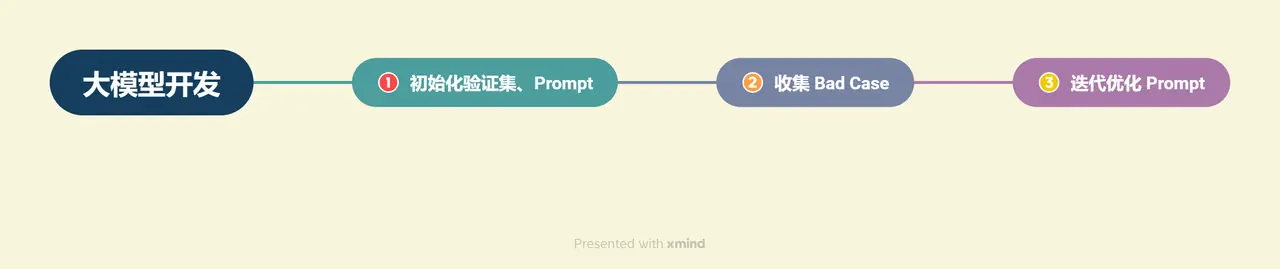
In this chapter, we will briefly describe the general process of large model development, and combined with the actual needs of the project, we will gradually analyze the work and steps to complete the project development.
1.4.1 General process of large model development
Combined with the above analysis, we can generally decompose large model development into the following processes:
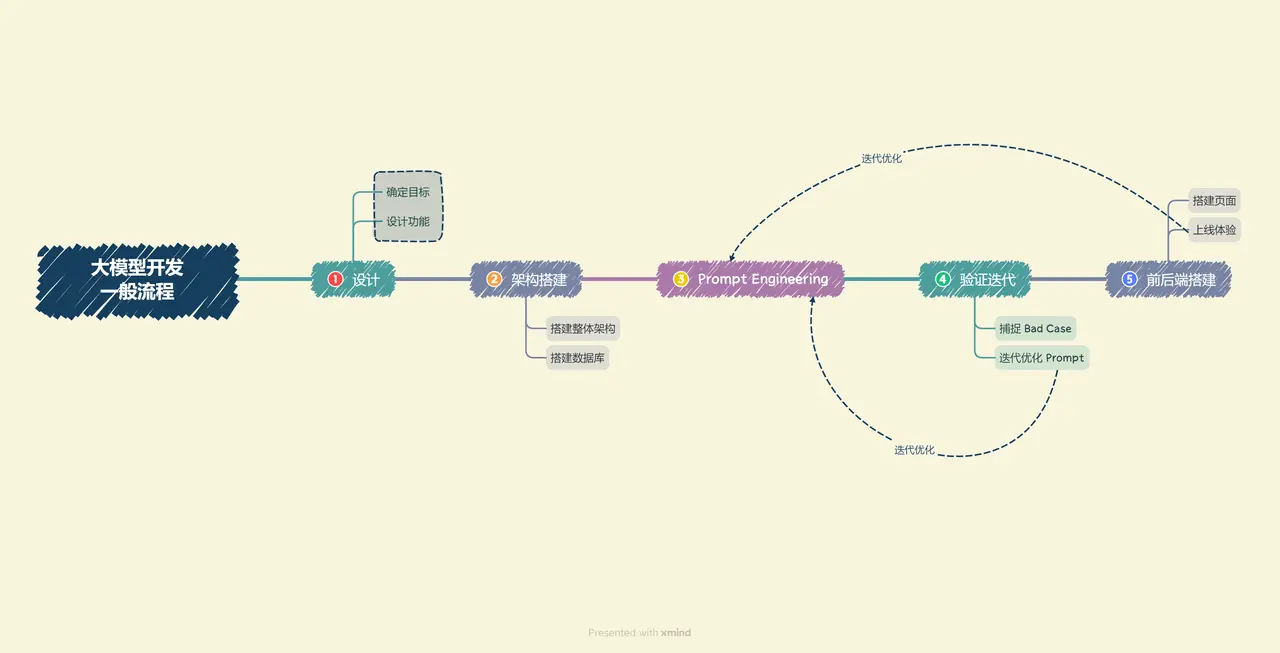
-
Determine goals. Before developing, we first need to determine the development goals, that is, the application scenarios, target groups, and core values of the application to be developed. For individual developers or small development teams, you should generally set minimum goals first, start by building an MVP (minimum viable product), and gradually improve and optimize.
-
Design function. After determining the development goals, you need to design the functions to be provided by the application and the general implementation logic of each function. Although we have simplified the disassembly of business logic by using large models, a clearer and in-depth understanding of business logic can often lead to better Prompt effects. Similarly, for individual developers or small development teams, they must first determine the core functions of the application, and then extend the design of the upstream and downstream functions of the core functions; for example, if we want to create a personal knowledge base assistant, the core function is to answer questions based on the content of the personal knowledge base. Then the upstream function of users uploading knowledge base, and the downstream function of users manually correcting model answers are sub-functions that we must also design and implement.
-
Build the overall architecture. At present, most large model applications adopt the architecture of specific database + Prompt + general large model. We need to build the overall structure of the project based on the functions we design, and realize the entire process from user input to application output. Generally speaking, we recommend developing based on the LangChain framework. LangChain provides the implementation of Chain, Tool and other architectures. We can carry out personalized customization based on LangChain and realize the overall architecture connection from user input to database to the final output of the large model.
-
Build database. Personalized large model applications need to be supported by a personalized database. Since large model applications require vector semantic retrieval, vector databases such as Chroma are generally used. In this step, we need to collect data, preprocess it, and then vectorize and store it in the database. Data preprocessing generally includes conversion from multiple formats to plain text, such as PDF, MarkDown, HTML, audio and video, etc., as well as cleaning of erroneous data, abnormal data, and dirty data. After completing the preprocessing, slicing and vectorization are required to build a personalized database.
-
Prompt Engineering. High-quality Prompt has a great impact on large model capabilities. We need to gradually and iteratively build high-quality Prompt Engineering to improve application performance. In this step, we should first clarify the general principles and techniques of Prompt design, build a small verification set derived from actual business, and design a Prompt that meets basic requirements and has basic capabilities based on the small verification set.
-
Verification iteration. Verification iteration is an extremely important step in large model development. It generally refers to continuously discovering Bad Cases and improving Prompt Engineering in a targeted manner to improve system effects and cope with boundary conditions. After completing the initial Prompt design in the previous step, we should conduct actual business testing, explore boundary conditions, find Bad Cases, and analyze the problems existing in Prompt in a targeted manner, so as to continuously iterate and optimize until we reach a more stable Prompt version that can basically achieve the goal.
-
Front-end and back-end construction. After completing Prompt Engineering and its iterative optimization, we have completed the core functions of the application and can fully utilize the powerful capabilities of large language models. Next we need to build the front and back ends and design the product page so that our application can go online and become a product. Front-end and back-end development is a very classic and mature field, so I won’t go into details here. We use Gradio and Streamlit, which can help individual developers quickly build visual pages to implement Demo online.
-
Experience Optimization. After completing the front-end and back-end construction, the application can be put online for experience. Next, you need to conduct long-term user experience tracking, record Bad Cases and user negative feedback, and then optimize accordingly.
1.4.2 Brief analysis of the process of building an LLM project (taking the knowledge base assistant as an example)
Below we will briefly analyze the 知识库助手项目 development process by combining this practical project with the overall process introduction above:
1.4.2.1 Project planning and demand analysis
-
Project Goal: Q&A assistant based on personal knowledge base
-
Core Functions
-
Vectorize the crawled and summarized MarkDown files and user-uploaded documents, and create a knowledge base;
-
Select the knowledge base and retrieve the knowledge fragments asked by the user;
-
Provide knowledge fragments and questions to obtain answers from large models;
-
Streaming reply;
-
Historical conversation records
-
Determine technical architecture and tools
-
Framework: LangChain
-
Embedding model: GPT, Wisdom, M3E
-
Database: Chroma
-
Large models: GPT, iFlytek Spark, Wen Xinyiyan, GLM, etc.
-
Front-end: Gradio and Streamlit
-
Data preparation and vector knowledge base construction
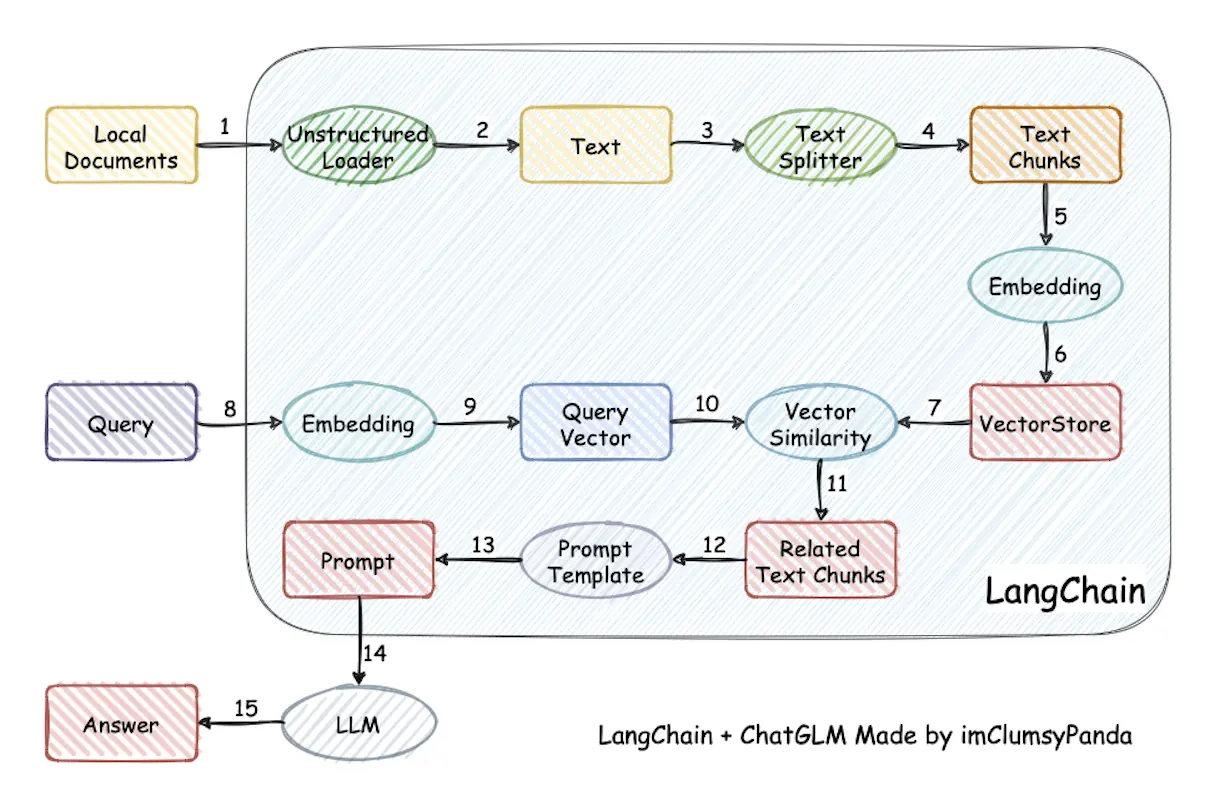
The implementation principle of this project is shown in the figure below (图片来源): load local document -> read text -> text segmentation -> text vectorization -> question vectorization -> match the top k most similar to the question vector in the text vector -> add the matched text to Prompt as context and question -> submit to LLM to generate an answer.
- Collect and organize documents provided by users
Common document formats used by users include PDF, TXT, MD, etc. First, we can use LangChain's document loader module to easily load documents provided by users, or use some mature Python packages to read them.
Due to the current limitations of using tokens in large models, we need to segment the read text and divide the longer text into smaller texts. At this time, a piece of text is a unit of knowledge.
- Vectorize document words
use文本嵌入(Embeddings)技术Vectorize the segmented documents so that semantically similar text segments have close vector representations. Then, store it in the vector database and complete索引(index)of creation.
Using a vector database to index each document fragment enables fast retrieval.
- Import the vectorized documents into the Chroma knowledge base and establish a knowledge base index
Langchain integrates with over 30 different vector databases. The Chroma database is lightweight and the data is stored in memory, which makes it very easy to launch and start using.
The user knowledge base content is stored in the vector database through Embedding. Then each user question will also go through Embedding. The vector correlation algorithm (such as the cosine algorithm) is used to find the most matching knowledge base fragments. These knowledge base fragments are used as context and are submitted to LLM as prompts together with user questions for answer.
-
Large model integration and API connection
-
Integrate large models such as GPT, Spark, Wenxin, and GLM, and configure API connections.
-
Write code to interact with the large model API to get answers to questions.
-
Implementation of core functions
-
Build Prompt Engineering to implement the large model answering function and generate answers based on user questions and knowledge base content.
-
Implement streaming replies, allowing users to engage in multiple rounds of conversations.
-
Add a historical conversation recording function to save the interaction history between the user and the assistant.
-
Iterative optimization of core functions
-
Conduct verification evaluation and collect Bad Cases.
-
Iteratively optimize core function implementation based on Bad Cases.
-
Front-end and user interaction interface development
-
Use Gradio and Streamlit to build the front-end interface.
-
Implement the functions for users to upload documents and create knowledge bases.
-
Design user interface, including question input, knowledge base selection, history record display, etc.
-
Deployment, testing and launch
-
Deploy the Q&A assistant to the server or cloud platform and ensure it is accessible on the Internet.
-
Conduct production environment testing to ensure system stability.
-
Go online and publish to users.
-
Maintenance and continuous improvement
-
Monitor system performance and user feedback, and handle problems in a timely manner.
-
Update the knowledge base regularly and add new documents and information.
-
Collect user needs and carry out system improvements and function expansion.
The entire process will ensure that the project proceeds smoothly from planning, development, testing to launch and maintenance, providing users with high-quality Q&A assistants based on personal knowledge bases.
Now that we have a preliminary understanding of the general process of large model development, we will introduce the entire development environment to ensure that everyone can smoothly develop the project.
- If you are a veteran, you can skip the rest of this chapter and go directly to the second part.
- The following two chapters mainly introduce the construction of two development environments for students who do not have a suitable development environment. You can read them on demand.
- Chapter 5 Main Introduction
阿里云服务器的基本使用、通过 SSH 远程连接服务器、jupyter notebook 的使用。- Chapter 6 mainly introduces
GitHub CodeSpaceusage, and how toGitHub CodeSpaceBuild a development environment in . (First determine whether you have a network environment that can smoothly access GitHub, otherwise it is recommended to use Alibaba Cloud)- If you already have a suitable development machine, you can jump directly to
7.环境配置Chapter to start configuring the development environment.
1.5 Basic use of Alibaba Cloud server
Alibaba Cloud is the world's leading cloud computing service provider, providing cloud computing, big data, artificial intelligence, security, enterprise applications, digital entertainment and other services to millions of customers in more than 200 countries and regions around the world. Alibaba Cloud's servers have stable performance and low prices, making them the first choice for many beginners. In particular, Alibaba Cloud's college plan allows you to receive cloud servers for free, which is very suitable for students. For new users, Alibaba Cloud also provides a free trial opportunity to use the cloud server for free for one year.
1.5.1 College Plan
The general rights and interests of college students are open to all Chinese college students, specifically including students with higher education status such as junior college, undergraduate, master's, doctoral, and part-time graduate students in mainland China, Hong Kong, Macao and Taiwan. On this basis, students from Alibaba Cloud's partner universities can enjoy 30% off exclusive rights.
Application link: https://university.aliyun.com/mobile?clubTaskBiz=subTask..11337012..10212..&userCode=1h9ofupt
-
Benefit 1: Chinese university students who have passed student certification can receive a 300 yuan non-threshold coupon.
-
Benefit 2: Chinese university students who have passed student certification and whose university is an Alibaba Cloud partner university can receive a 300-yuan no-threshold coupon and a 30% discount on Alibaba Cloud public cloud products (except special products). The original order price does not exceed 5,000 yuan.
The current partner universities include: Tsinghua University, Peking University, Zhejiang University, Shanghai Jiao Tong University, University of Science and Technology of China, South China University of Technology and Hong Kong University of Science and Technology (Guangzhou). We are negotiating with more universities, so stay tuned!
 Click Receive Now in the picture and scan the QR code to log in with your real-name authenticated Alipay for verification.
Click Receive Now in the picture and scan the QR code to log in with your real-name authenticated Alipay for verification.
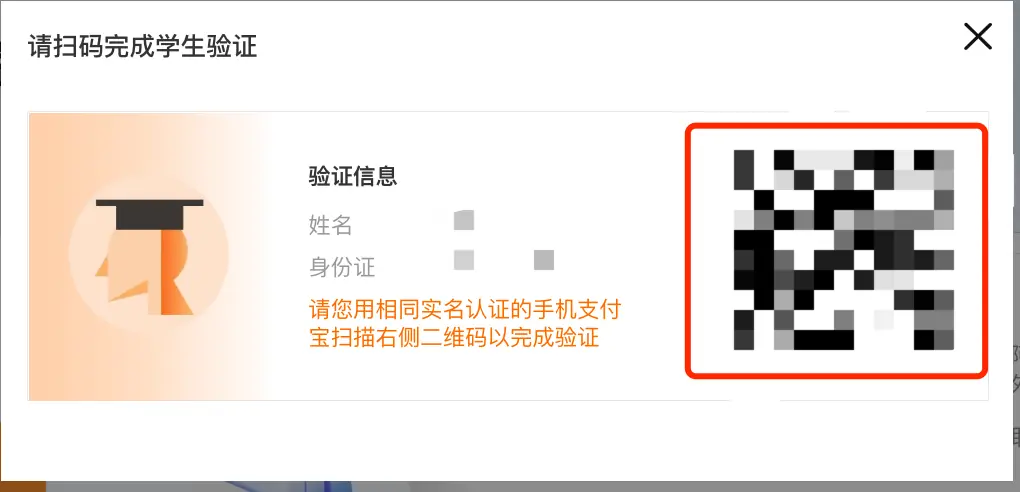
The user is a teacher (including postdoctoral fellow) from a partner university and has completed identity authentication in accordance with the activity requirements.
The current partner universities include: Tsinghua University, Peking University, Zhejiang University, Shanghai Jiao Tong University, University of Science and Technology of China, South China University of Technology and Hong Kong University of Science and Technology (Guangzhou). We are negotiating with more universities, so stay tuned!
- Alibaba Cloud offers an exclusive 50% discount on all public cloud products (except special products) and sets up exclusive service channels to accelerate scientific research and teaching.
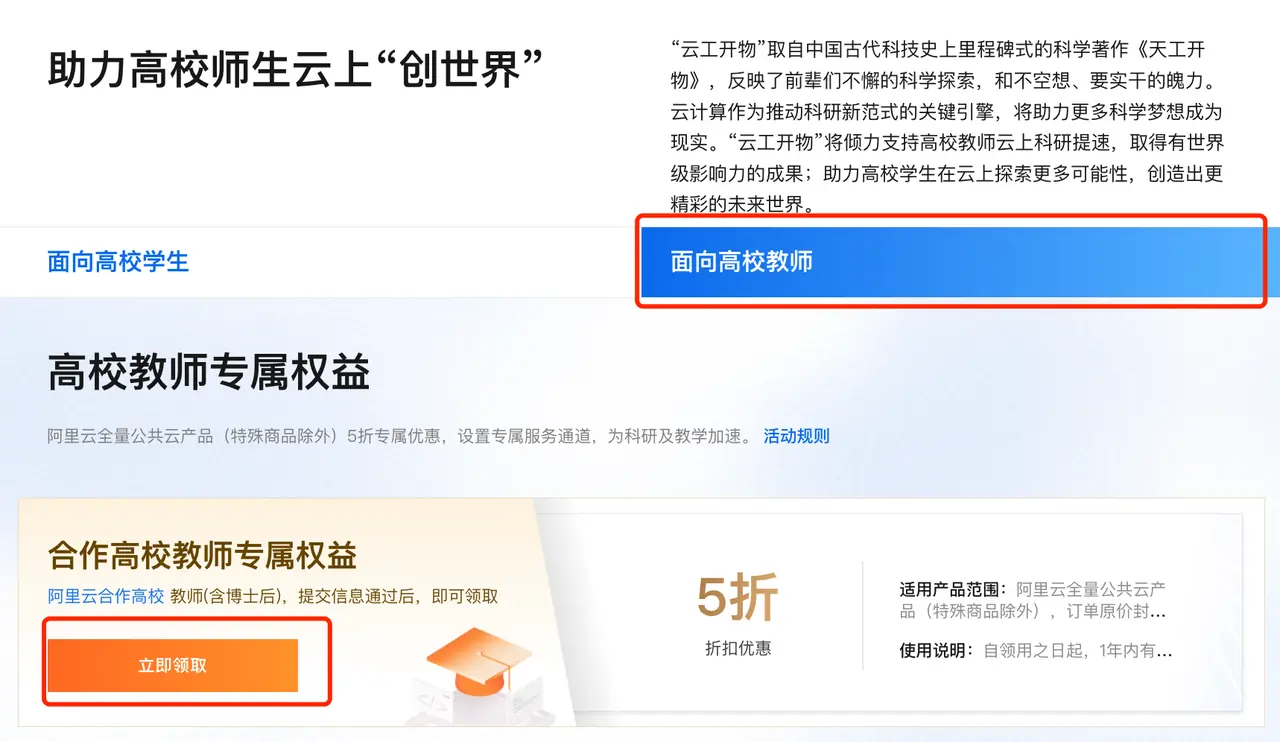
Note: It is best to confirm that the coupon has arrived before purchasing the product; the coupon information is in用户中心-卡券管理-优惠券管理Check.
https://developer.aliyun.com/plan/student
Application link: https://free.aliyun.com/?crowd=personal
It is recommended that everyone apply here云服务器 ECS, the monthly free quota is 280 yuan, valid for 3 months. The approximate configuration is as follows:
- e series 2-core 2GB or 2-core 4GB (free quota of 200 yuan per month);
- 80 yuan free monthly quota for public network traffic (can be used to offset 100GB of domestic regional traffic)
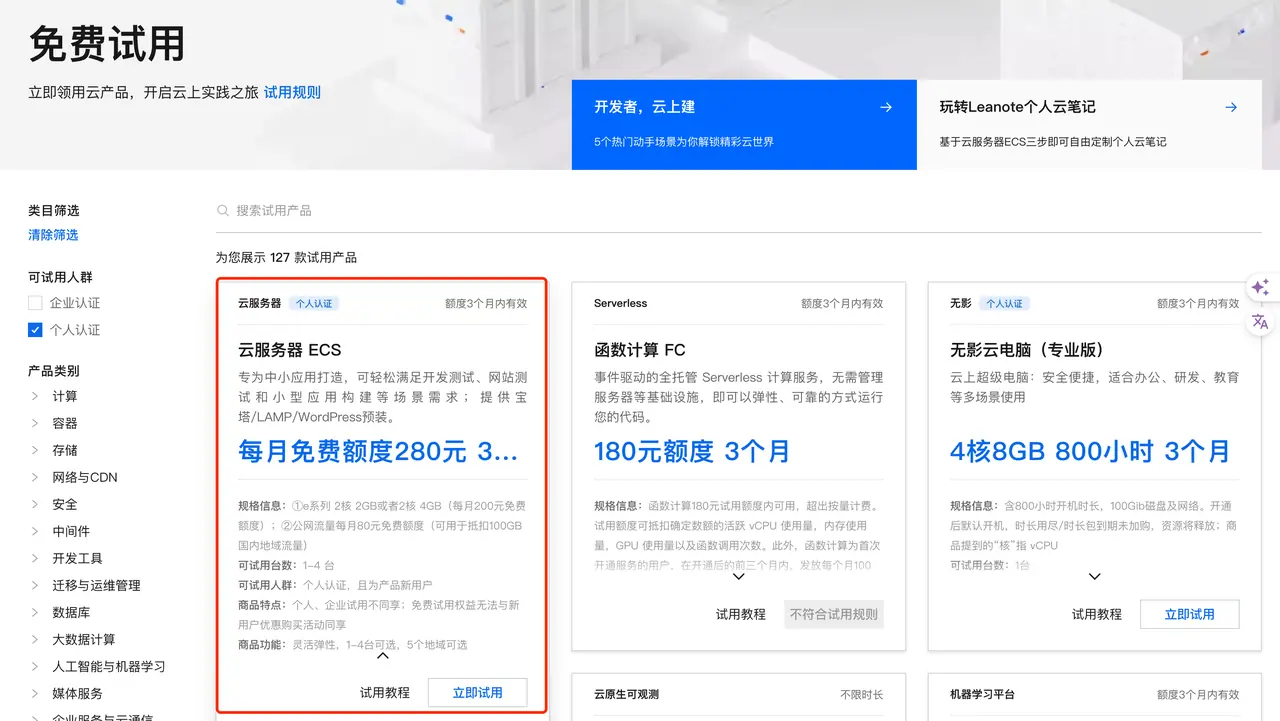
1.5.2 Guide to creating cloud server
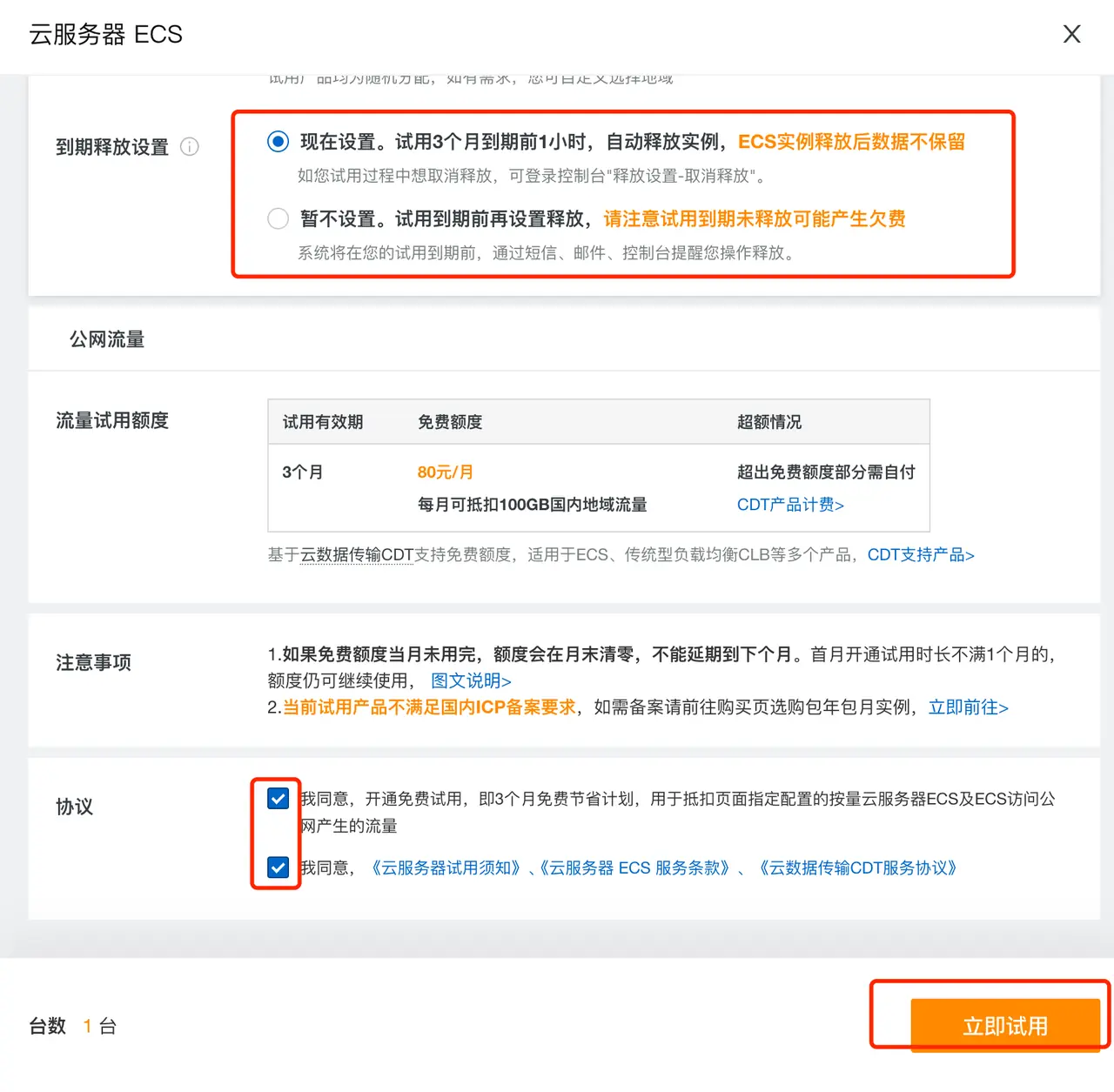
here to select云服务器 ECSTake the configuration as an example, select the minimum configuration and select the systemUbuntu,
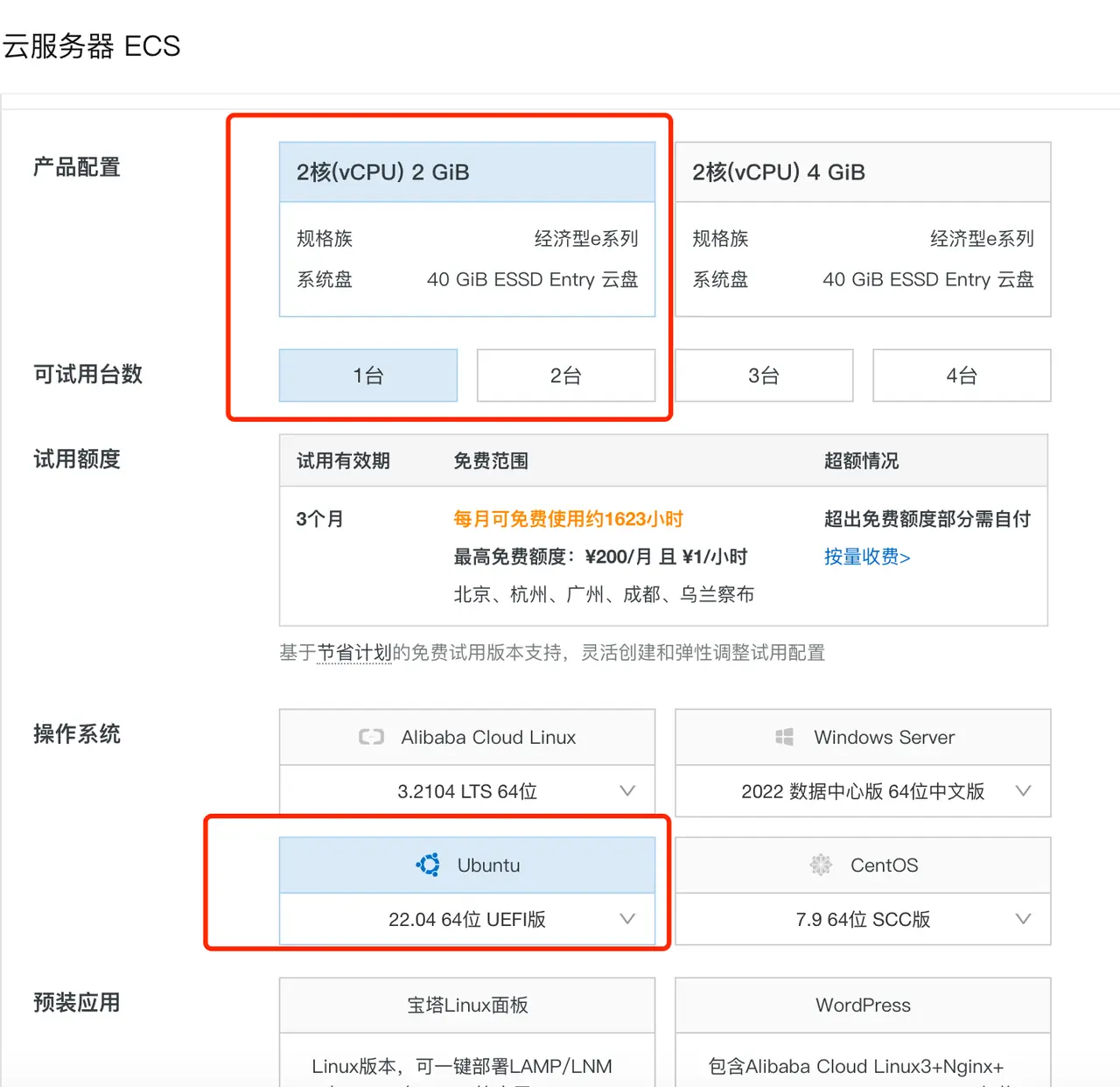 During the trial, fill in "Automatic release instance" in the expiration release setting, so that no fees will be incurred after expiration.
During the trial, fill in "Automatic release instance" in the expiration release setting, so that no fees will be incurred after expiration.
After the creation is completed, click Trial or 链接 to see the instance we just created.
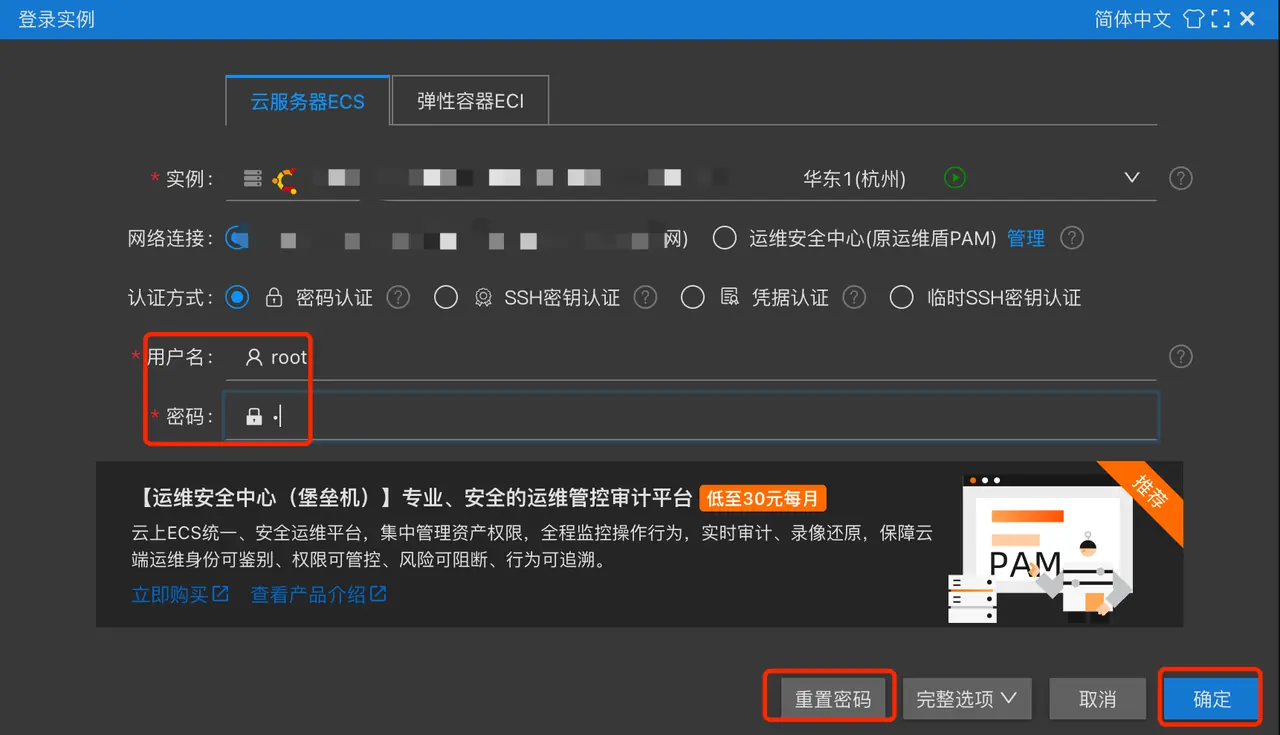
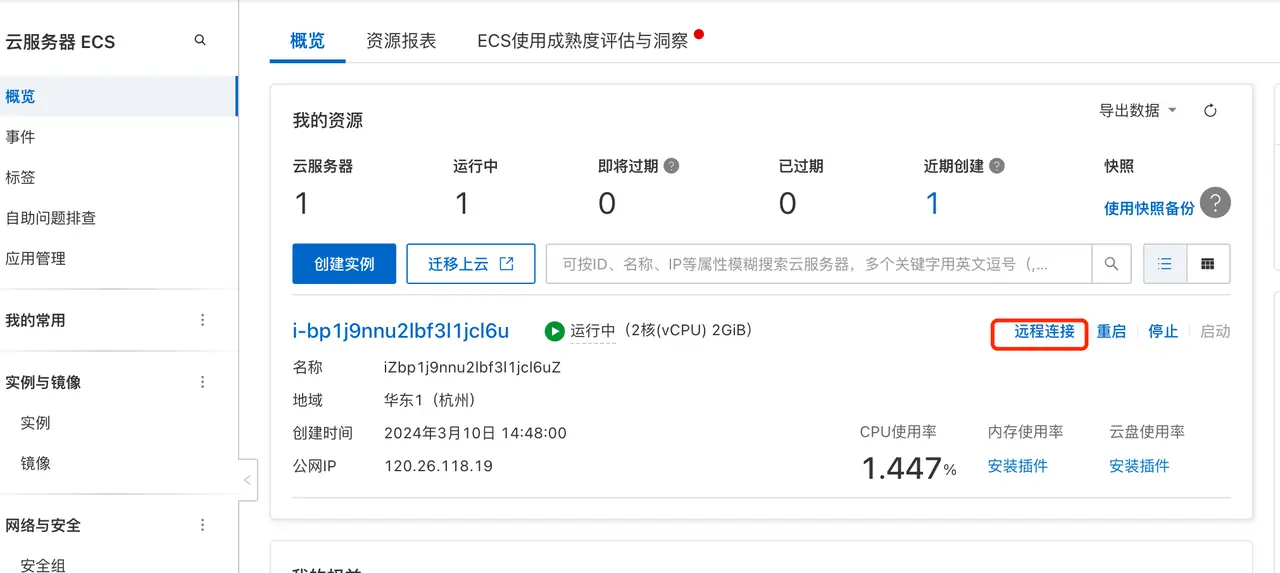 Click Remote Connection and click Log In Now.
Click Remote Connection and click Log In Now.
 The default password is root;
The default password is root;
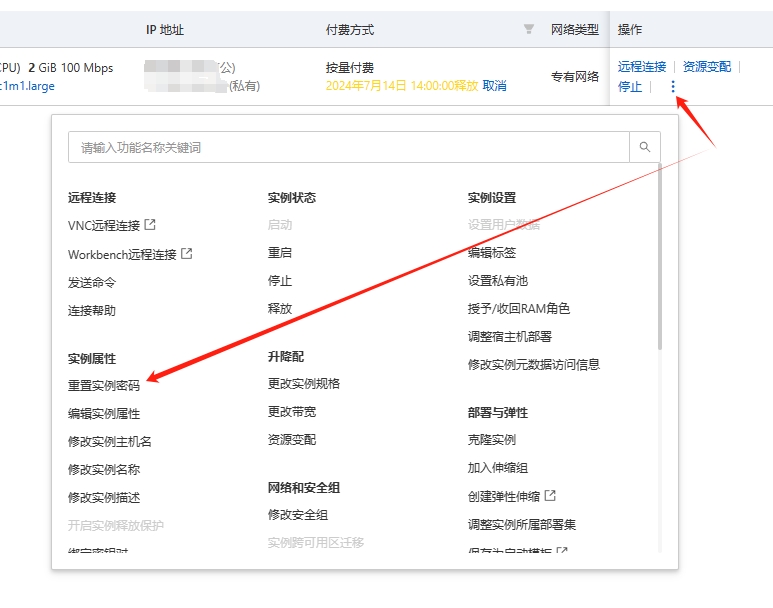
 If login is not allowed, please modify the server configuration according to 链接.
[Simple processing method: On the cloud server management console page, click the three dots near 'Remote Connection' and choose to reset the instance password. Just log in again. 】
If login is not allowed, please modify the server configuration according to 链接.
[Simple processing method: On the cloud server management console page, click the three dots near 'Remote Connection' and choose to reset the instance password. Just log in again. 】
Then you can enter the environment to study! ! !
1.5.3 VSCode connects to remote server
Visual Studio Code(VSCode)It is a free, open source, modern code editor developed by Microsoft. It is favored by developers for its lightweight, high performance and wide range of programming language support. The core features of VSCode include:
- Cross-platform: Supports Windows, macOS and Linux operating systems.
- Extension Market: Provides a wealth of extension plug-ins to adapt to different development needs.
- Built-in Git support: Convenient for version control operations.
- Debugging Tool: Built-in powerful debugging function, supporting multiple programming languages.
- Intelligent Sensing: Provides intelligent prompt functions such as code completion and parameter information.
- Integrated Terminal: Built-in terminal, you can perform command line operations without switching.
- Customization: Supports personalized settings such as themes and key bindings.
The flexibility and ease of use of VSCode make it one of the preferred code editing tools for developers.
Here we choose VSCode to connect to the remote server, so that we can directly operate the remote server in the local editor.
-
Install the SSH plugin Open VSCODE's plug-in market, search for SSH, and find
Remote - SSHPlugin and install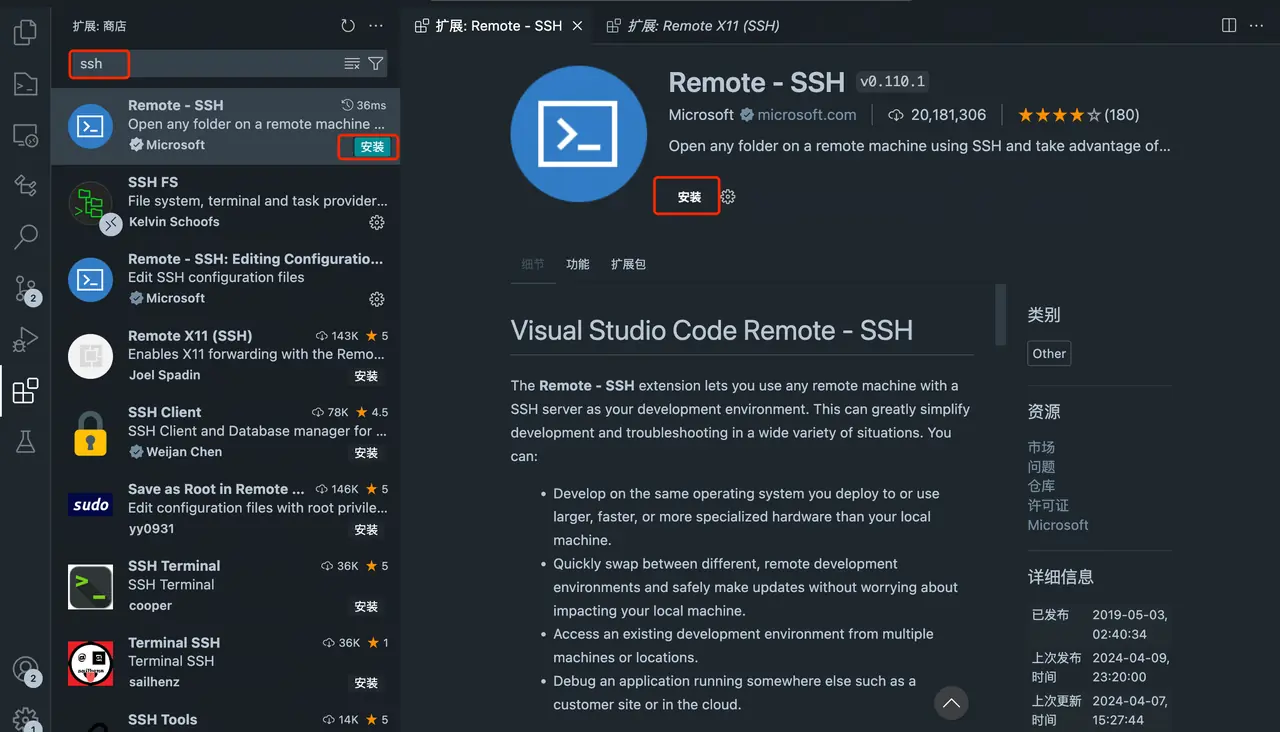
-
Get server IP Open 实例列表 of Alibaba Cloud server Find the public IP address of the server we need to connect to and copy it.
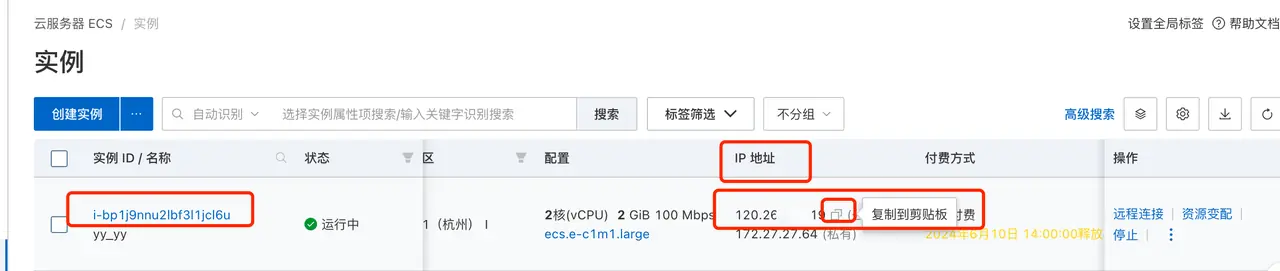 Open the editor of the remote server that can be connected. Here we take VSCODE as an example.
Open the editor of the remote server that can be connected. Here we take VSCODE as an example. -
Configure SSH Open the one you just downloaded
远程资源管理器Plugin, add server SSH,ssh -p port username@ipThe port is generally configured as 22, username can be root or a customized username Replace IP with the IP of the server Select a local SSH profile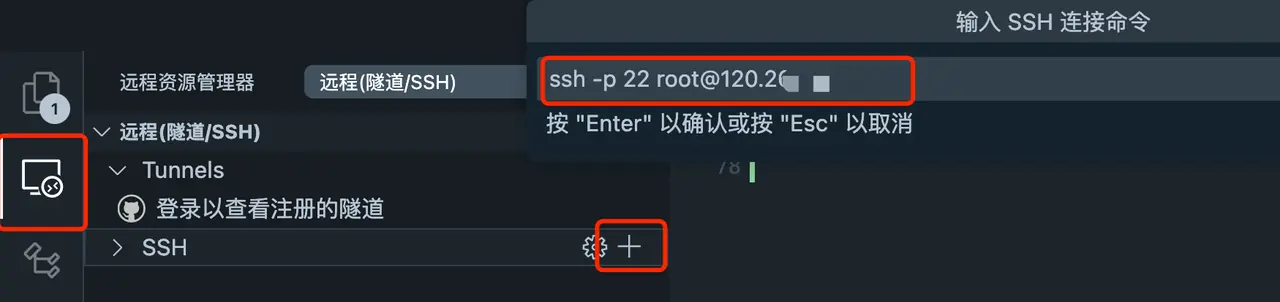 Click the link in the lower right corner to enter the server
Click the link in the lower right corner to enter the server

-
Connect When we connect later, we can continue to click on the left
远程资源管理器Find our server, there are two options on the right.
- The arrow opens this window
- If there is a plus sign in the upper left corner, a new window will open.

- Open the directory Then click to open the folder and enter the required directory to open it.
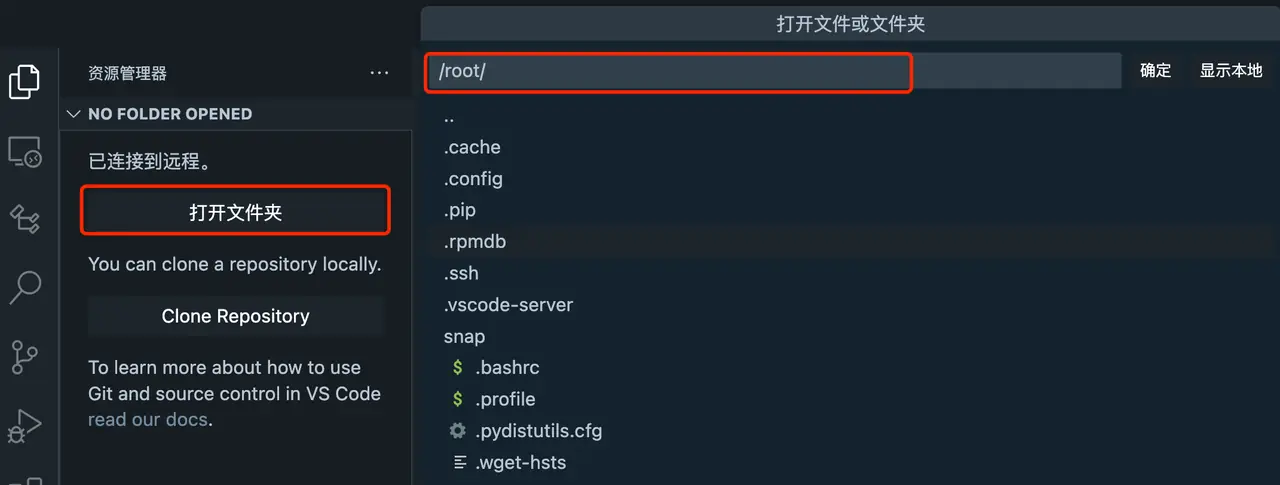
Then you can have fun programming! ! !
1.5.4 Jupyter Notebook usage
Jupyter Notebook is an open source交互式计算环境, which allows users to create and share documents containing live code, equations, visualizations, and text. Its name comes from the three core programming languages it supports: Julia, Python, and R, which is where the name "Ju-pyt-er" comes from. Files written in Jupyter Notebook have the suffix.ipynb
Key features of Jupyter Notebook include:
-
Interactive Programming: Users can write code and execute it in separate cells,
立即看到代码运行结果, which is very useful for data analysis, machine learning, scientific computing and other fields. -
Multi-language support: Although originally designed for Julia, Python and R, Jupyter now supports more than 40 programming languages through the use of corresponding kernels.
-
Rich display functions: Jupyter Notebook supports Markdown, allowing users to add rich media content such as formatted text, images, videos, HTML, LaTeX, etc., making documents more vivid and informative.
-
Data Visualization: Jupyter Notebook is seamlessly integrated with many data visualization libraries (such as Matplotlib, Plotly, Bokeh, etc.), and charts and visual data can be generated directly in Notebook.
-
Easy to share: Notebook files can be easily shared via email, cloud services, or the Jupyter Notebook Viewer, so others can view the content, run the code, and even leave comments.
-
Extensibility: Jupyter has a large number of extension plug-ins that can enhance its functionality, such as interactive widgets, code auto-completion, theme replacement, etc.
-
Scientific computing tool integration: Jupyter Notebook can be integrated with many scientific computing and data analysis tools, such as NumPy, Pandas, SciPy and other Python libraries, making data processing and analysis more convenient.
Jupyter Notebook is a widely used tool by data scientists, researchers, educators, and students alike to advance open science and education, making it easier to share and reproduce research results.
This tutorial uses Jupyter Notebook to write and run code, which facilitates us to write and debug code.
VSCODECurrently, Jupyter Notebook files can be opened directly without installing any plug-ins. (You can also follow the next chapter to install and configure the plug-in)
Notebook documents are composed of a series of cells, mainly in the following two forms.
- Code Cell: Enter the code in the code cell and press
Shift + EnterYou can run the code in this cell and display the output below. - Markdown cells: use
MarkdownSyntax for writing text in cells. You can create titles, lists, links, formatted text, etc. and useCtrl + Enterto render the current Markdown cell.
Usually we use code cells to write code and run it in time to view the results. And use the following shortcut keys to improve efficiency:
Cell Edit
Enter: Enter editing mode.Esc: Exit edit mode.
Cell operations
A: Insert a new cell above the current cell.B: Insert a new cell below the current cell.D(Double press): Delete the current cell.Z: Undo the delete operation.C: Copy the current cell.V: Paste the previously copied cells.X: Cut the current cell.Y: Convert the current cell to a code cell.M: Convert the current cell to a Markdown cell.Shift + M: Switch the Markdown rendering state of the cell.
Code Execution and Debugging
Shift + Enter: Run the current cell and jump to the next cell.Ctrl + Enter: Run the current cell without jumping to the next cell.Alt + Enter: Runs the current cell and inserts a new cell below.Esc: Enter command mode.Enter: Enter editing mode.Ctrl + Shift + -: Split the current cell into two cells.Ctrl + Shift + P: Open the command panel, where you can search and execute various commands.
Navigation and Window Management
Up/DownorK/J: Move up and down between cells.Home/End: Jump to the beginning or end of Notebook.Ctrl + Home/Ctrl + End: Jump to the first or last cell of the current Notebook.Tab: Switch to the next panel in Notebook view (for example, from the editor to the output or metadata panel).Shift + Tab: Switch to the previous panel in Notebook view.
Other useful shortcut keys
H: Show or hide the Notebook sidebar.M: Convert the current cell to a Markdown cell.Y: Convert the current cell to a code cell.
At present, we already have the necessary foundation for development, and we can go directly to
7.环境配置Configure the environment.
1.6 GitHub Codespaces Overview & Environment Configuration (Elective)
First determine whether there is a network environment that can smoothly access GitHub > Otherwise, it is still recommended to use Alibaba Cloud
1.6.1 Create the first codespace
Codespace is a development environment hosted in the cloud. Projects can be customized for GitHub Codespaces by committing configuration files to the repository (often referred to as "configuration as code"), which creates repeatable codespace configurations for all users of the project. See "开发容器简介" for details.
- Open the URL link: https://github.com/features/codespaces
- Log in to your GitHub account
- Click on the icon Your repositories
- After entering your own repository list, click the icon New to create a new repository
- You can set it according to your needs. For convenience and security, it is recommended to check Add a README file and select Private (because the API key is used in the course, please pay attention to protecting privacy). After the setting is completed, click Create repository
- After creating the repository, click code to select Codespaces, and click the icon Create codespace on main
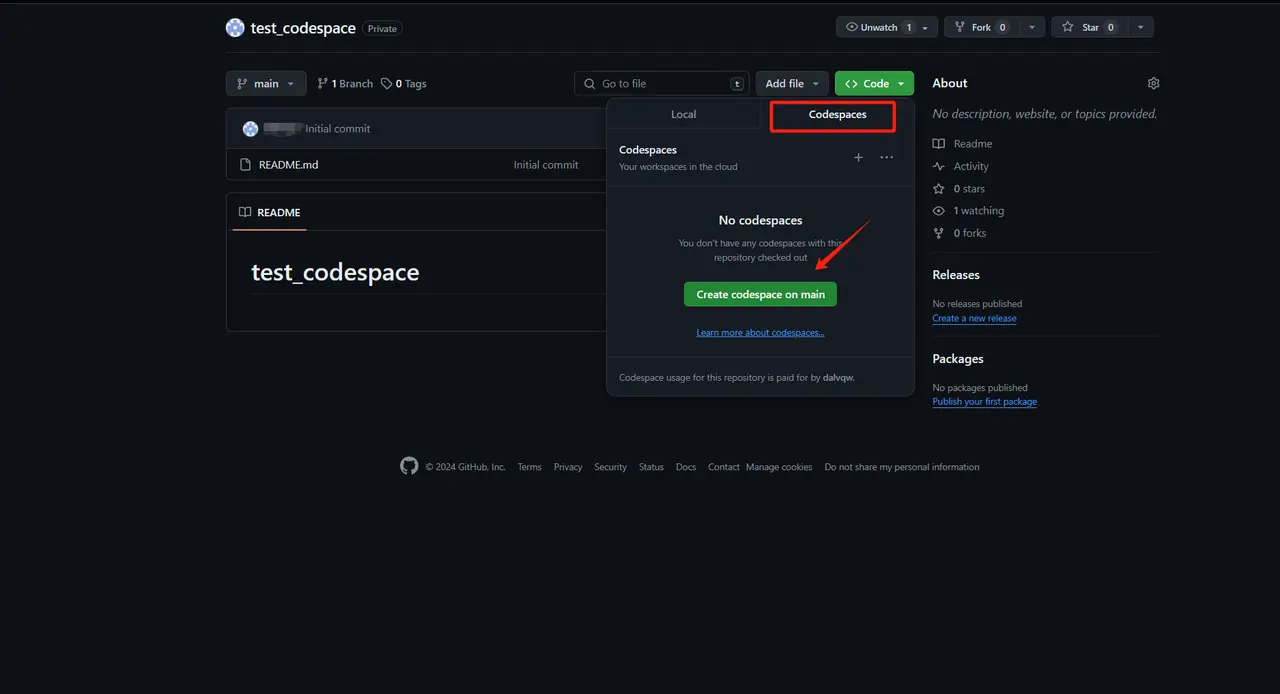
- After waiting for a period of time, the following interface will appear. The next operation is the same as VSCode. You can install plug-ins and adjust settings as needed.
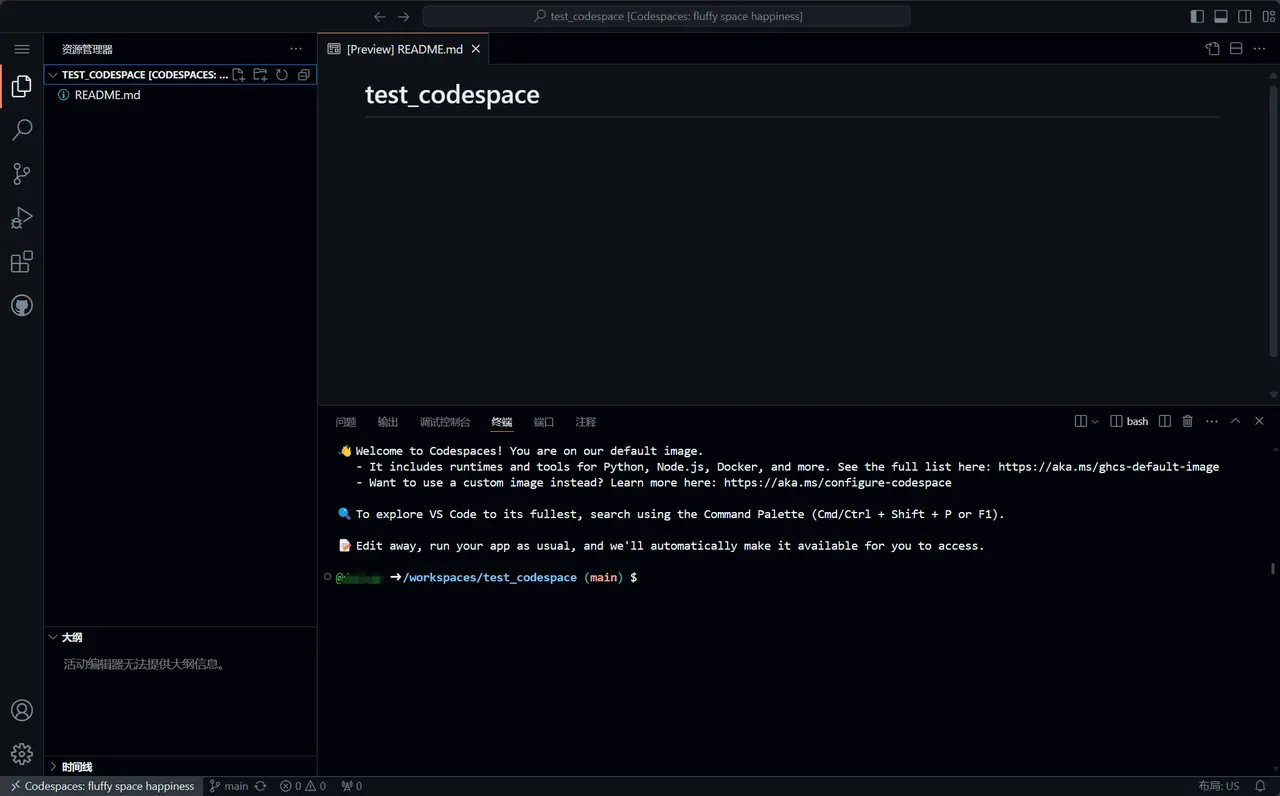
Reference7.环境配置middle1.2 通用环境配置Just configure the environment, you can skip the first two steps.
Since each repository can set up an independent codespace, we do not need to install the conda environment here. And because the GitHub server is abroad, there is no need to configure a domestic mirror source.
Reference7.环境配置Part 2. VSCode configures the Python environment
`Configure the environment
Note: After installing all configurations for the first time, you need to restart the codespace
1.6.2 Local VSCode connection Codespace (not required)
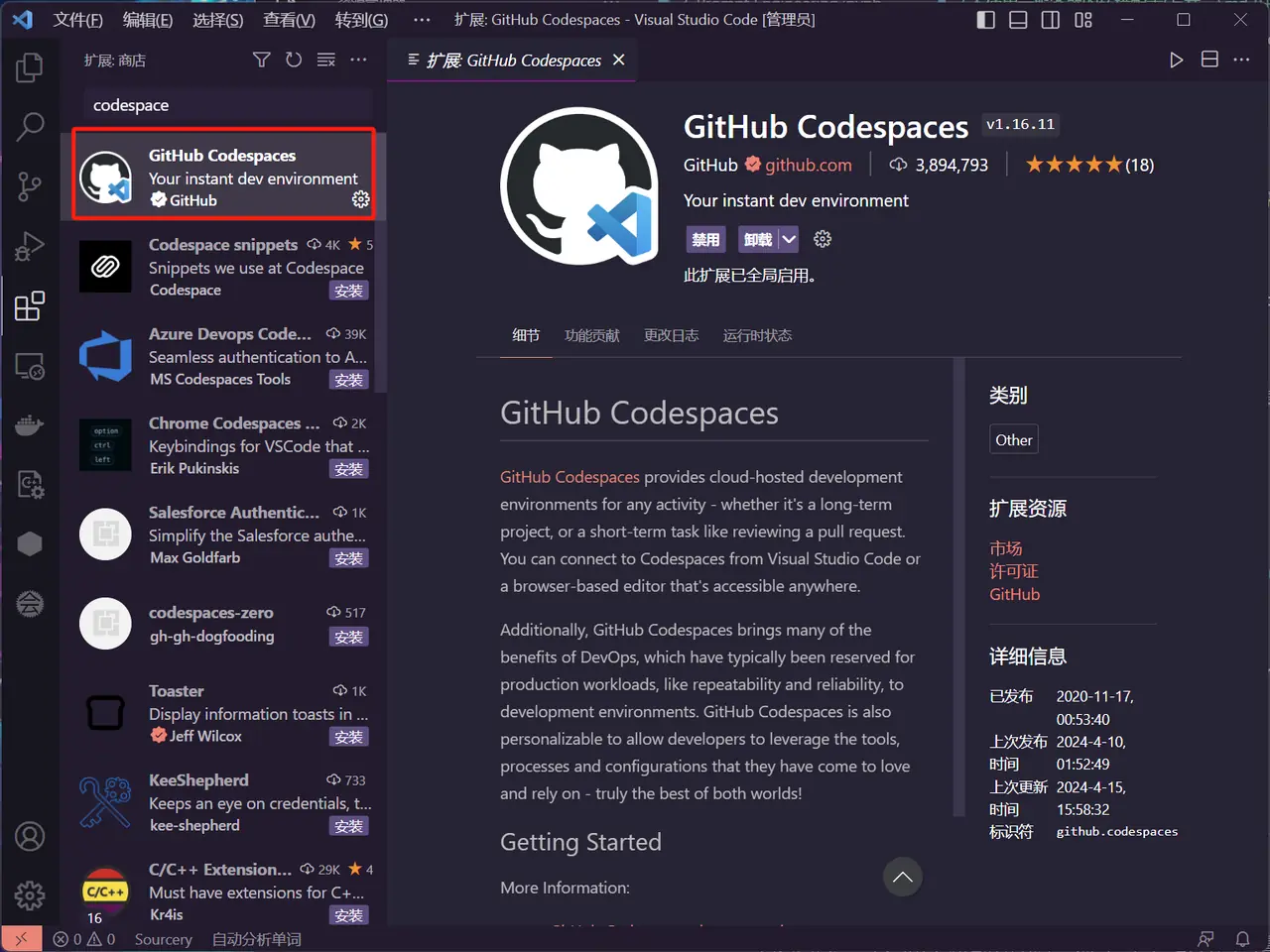
- Open VSCode, search for codespace and install the plug-in
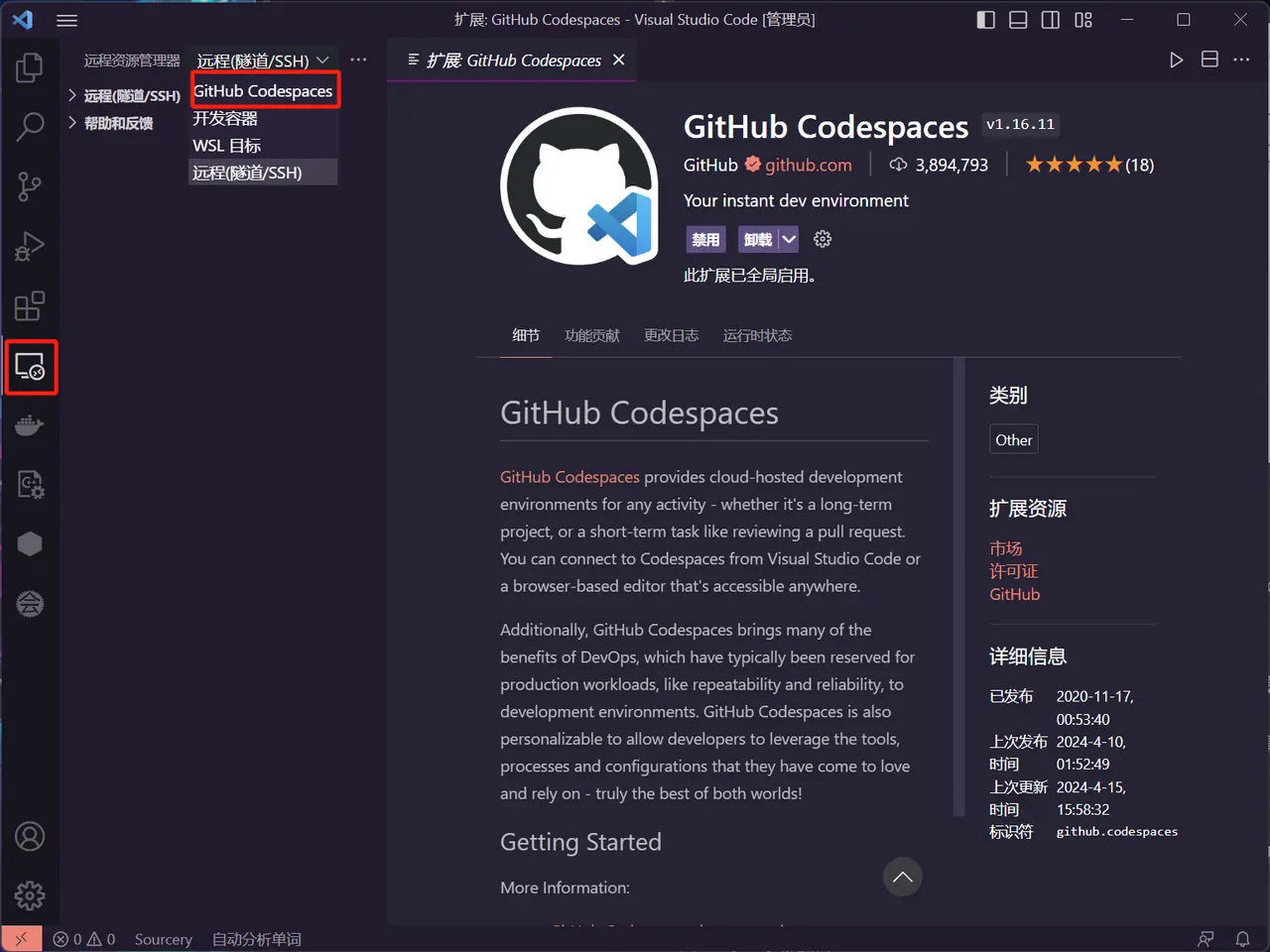
- In the activity bar of VSCode, click the Remote Resource Manager icon
- Log in to GitHub and follow the prompts to log in.
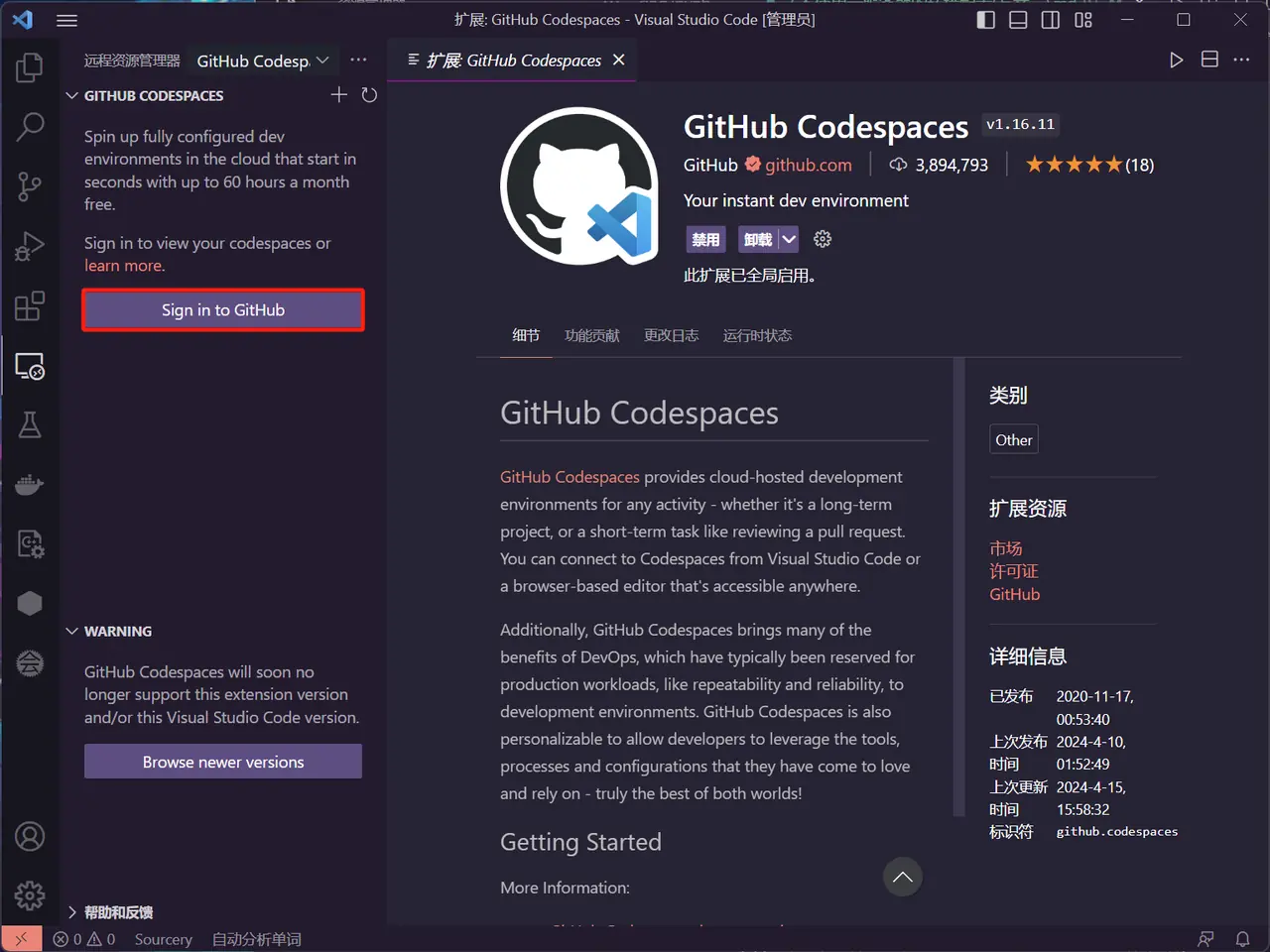
- You can see that the codespace we just created is here, click the red box connection icon
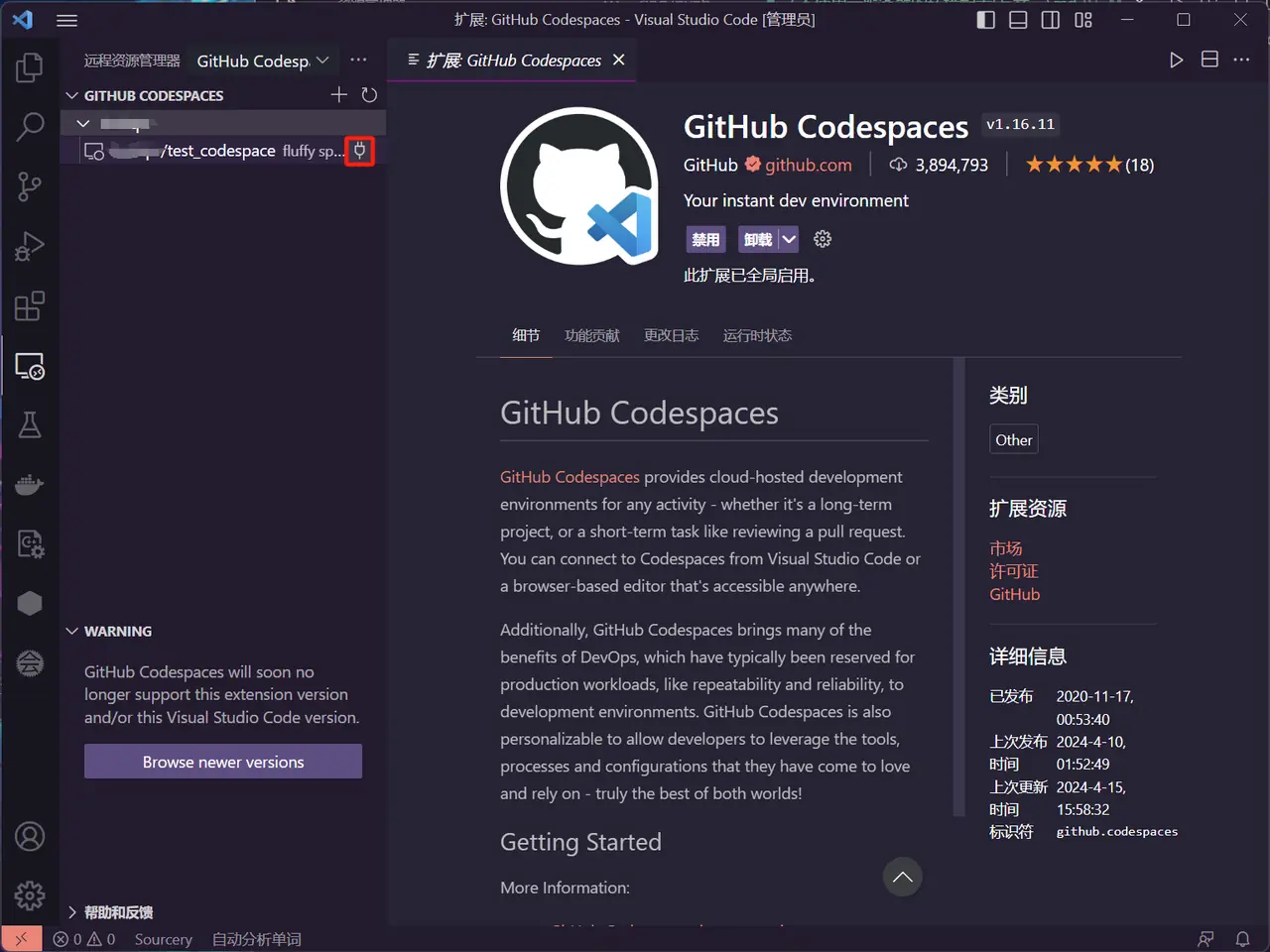
- Successfully connected to the codespace
- VSCode 官方配置文档
Note
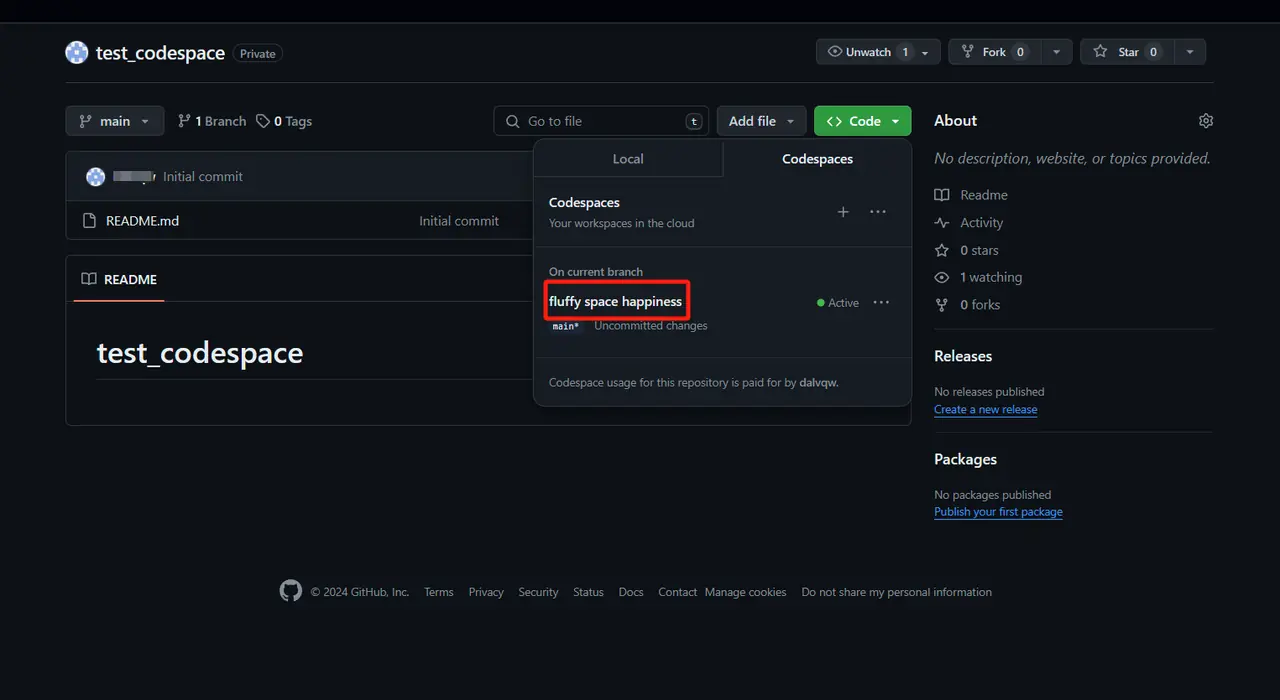
- After the web page is closed, find the newly created repository and click the red box to select the content to re-enter the codespace.
- Free quota
After finding the GitHub account settings, you can see the remaining free quota in Plans and usage
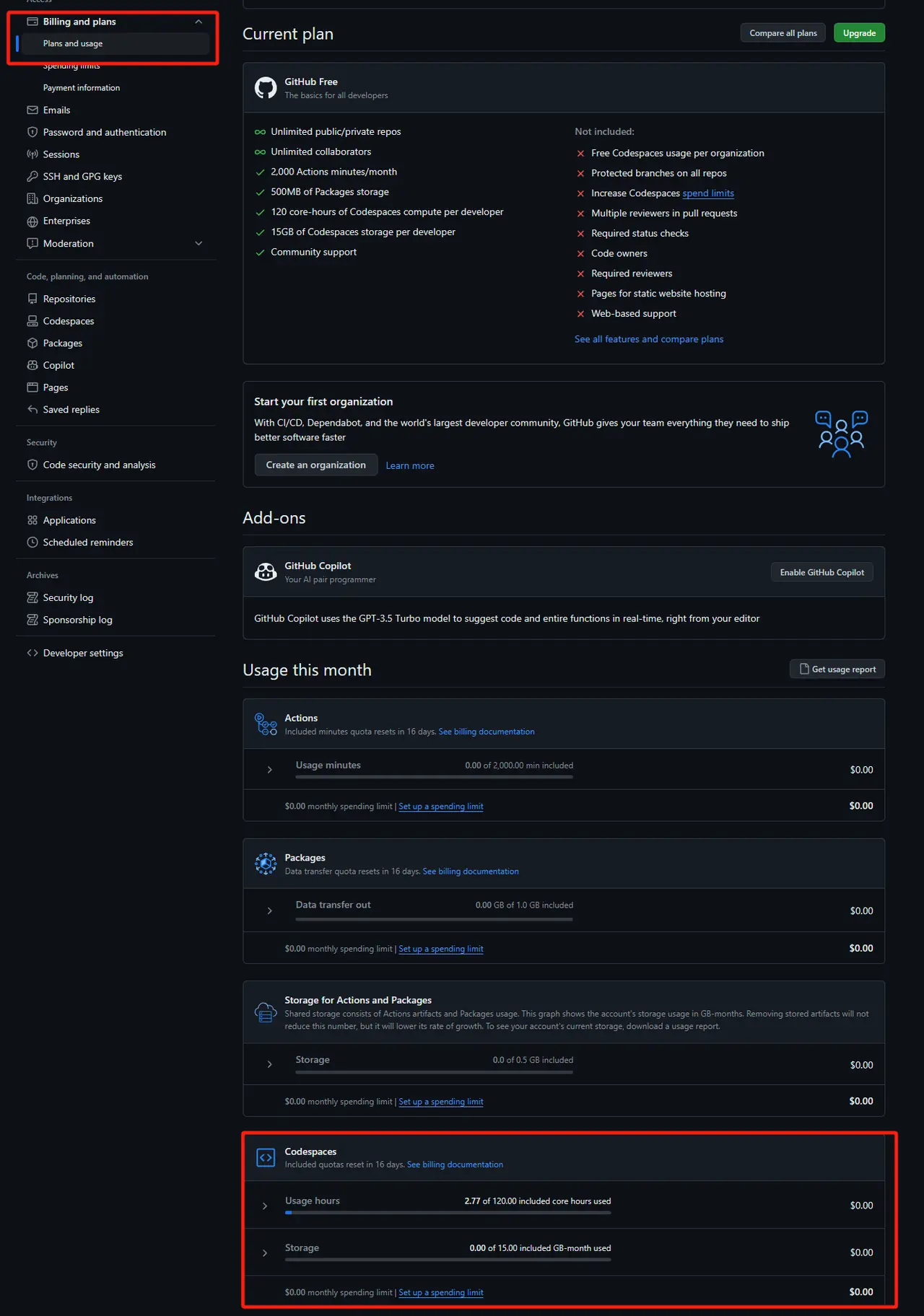
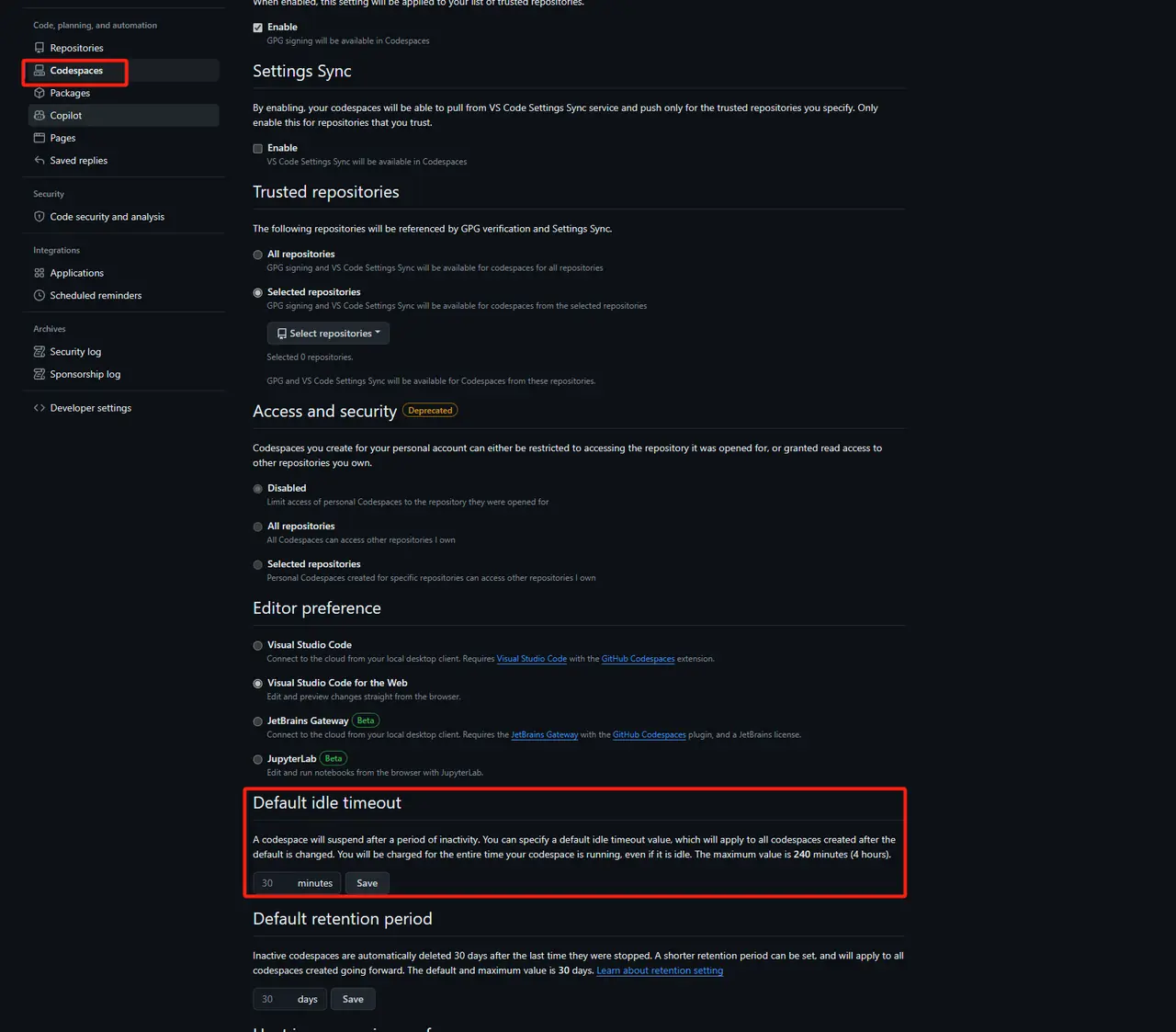
- Codespace settings, it is recommended to adjust the suspension time (too long time will waste credit)
- Because the codespace can be accessed through the web, the most important thing is of course that you can carry your tablet with you to access the web for programming learning
At present, we already have the necessary foundation for development. In the next chapter, we will introduce in detail the required environment configuration.
1.7 Environment configuration
This chapter mainly provides some necessary environment configuration guidelines, including code environment configuration, Python environment configuration of the VSCODE code editor, and some other resource configurations used.
Here we introduce each step of code environment configuration in detail, which is divided into two parts: basic environment configuration and general environment configuration to meet the needs of different users and environments.
-
Basic environment configuration section: Suitable for environment configuration beginners or new server environments (such as Alibaba Cloud). This section describes how to generate and add an SSH key to GitHub, as well as install and initialize the conda environment.
-
General environment configuration section: suitable for users with certain experience, local installations with existing environment base, or completely independent environments (such as GitHub Codespace). This part introduces how to create and activate the conda virtual environment, clone the project repository, switch to the project directory, and install the required Python packages. In order to speed up the installation of Python packages, we also provide some domestic image sources. For a completely independent environment, you can skip the first two steps about virtual environment (conda) configuration.
1.7.1 Basic environment configuration (configuring git and conda)
-
Generate ssh key
ssh-keygen -t rsa -C "youremail@example.com" -
Add the public key to github
cat ~/.ssh/id_rsa.pubCopy the output content, open github, click the avatar in the upper right corner, and selectsettings->SSH and GPG keys->New SSH key, paste the copied content into key, and clickAdd SSH key。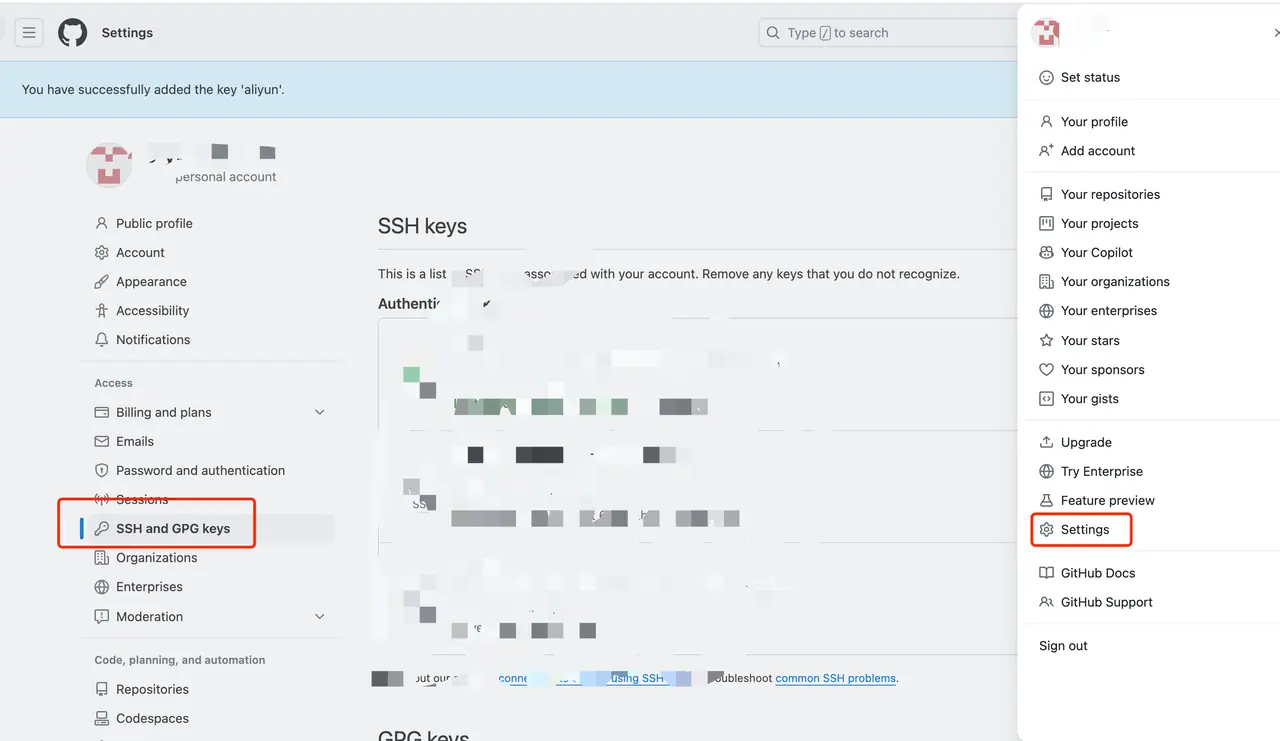
-
Install conda environment
-
linux environment (usually linux environment is used)
-
Installation:
-
Initialization:
-
Create a new terminal and check whether conda is installed successfully.
conda --version -
macOS environment
-
Installation
-
Initialization:
-
Create a new terminal and check whether conda is installed successfully.
conda --version -
windows environment
-
Download:
curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe -o miniconda.exe -
Installation: Click downloaded
miniconda.exe, installation guide to install -
Open Anaconda Prompt in the menu and check whether conda is installed successfully.
conda --version -
Delete the installation package:
del miniconda.exe -
Please refer to the following
通用环境配置Partially perform subsequent configuration
1.7.2 General environment configuration
- Create a new virtual environment
conda create -n llm-universe python=3.10 - Activate the virtual environment
conda activate llm-universe - Clone the current repository in the path where you want to store the project
git clone git@github.com:datawhalechina/llm-universe.git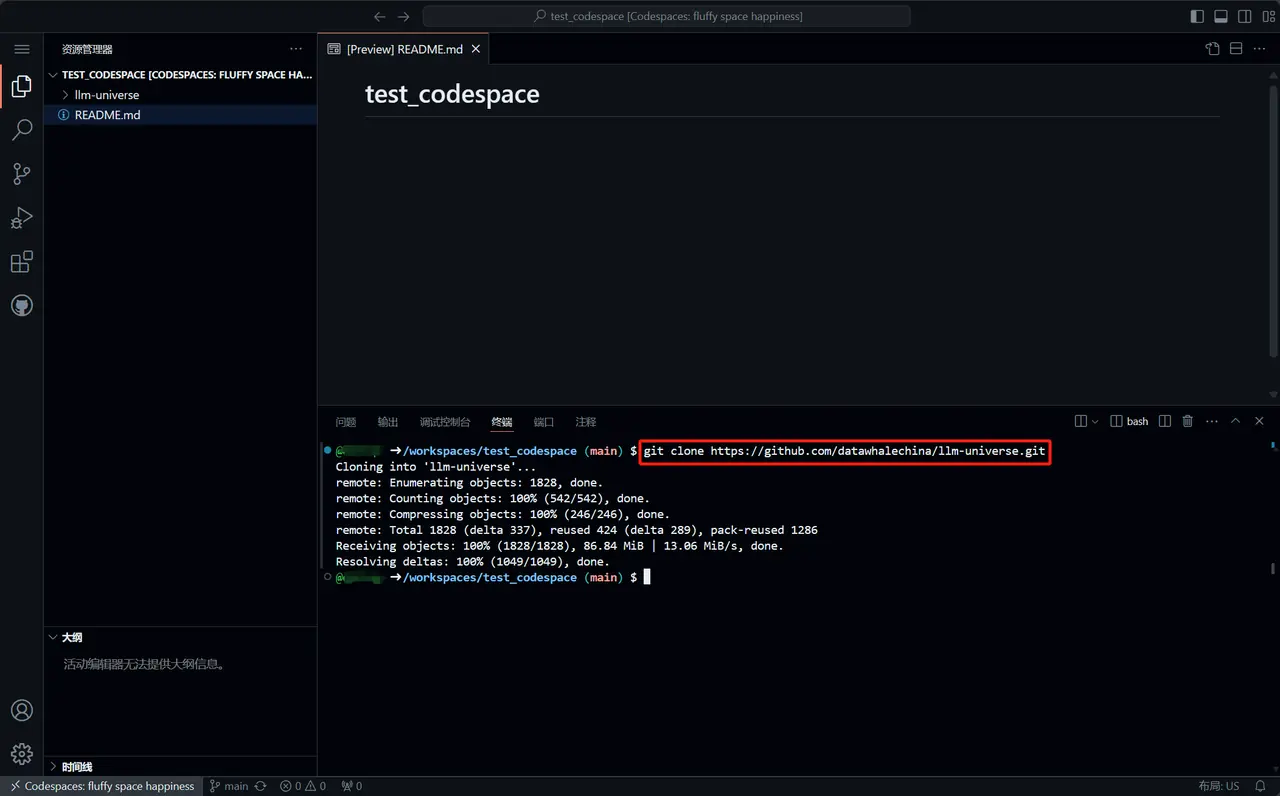
- Change directory to llm-universe
cd llm-universe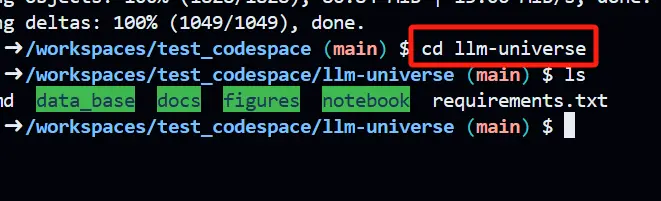
- Install required packages
pip install -r requirements.txt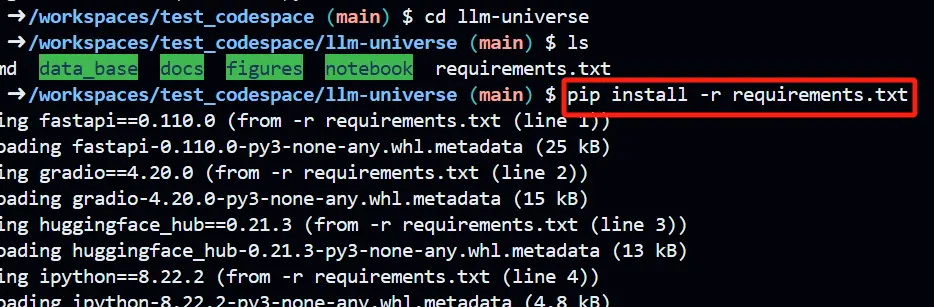 Installation can usually be accelerated through Tsinghua Source
Installation can usually be accelerated through Tsinghua Source
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
Here is a list of commonly used domestic image sources. If the image source is not stable, you can switch as needed: Tsinghua: https://pypi.tuna.tsinghua.edu.cn/simple/ Alibaba Cloud: http://mirrors.aliyun.com/pypi/simple/ University of Science and Technology of China: https://pypi.mirrors.ustc.edu.cn/simple/ Huazhong University of Science and Technology: http://pypi.hustunique.com/simple/ Shanghai Jiao Tong University: https://mirror.sjtu.edu.cn/pypi/web/simple/ Douban: http://pypi.douban.com/simple
1.7.3 VSCode configuration Python environment
- Install Python plug-in
This tutorial is developed based on Python language. For a better development experience, we need to install the Python plug-in.
Search in the plug-in marketPython,turn upPythonplugin and install it.
 At this time, when we execute Python code, our Python environment will be automatically recognized and code completion and other functions will be provided to facilitate our development.
At this time, when we execute Python code, our Python environment will be automatically recognized and code completion and other functions will be provided to facilitate our development.
-
Install the Jupyter plug-in In this tutorial, we use Jupyter Notebook for development, so we need to install the Jupyter plug-in. Search in the plug-in market
Jupyter,turn upJupyterplugin and install it.
-
Configure the Python environment for Jupyter Notebook
-
Open a Jupyter Notebook
-
Click on the upper right corner
选择 Python 解释器(显示内容会根据选择环境的名称变化), select the Python environment of the current Jupyter Notebook.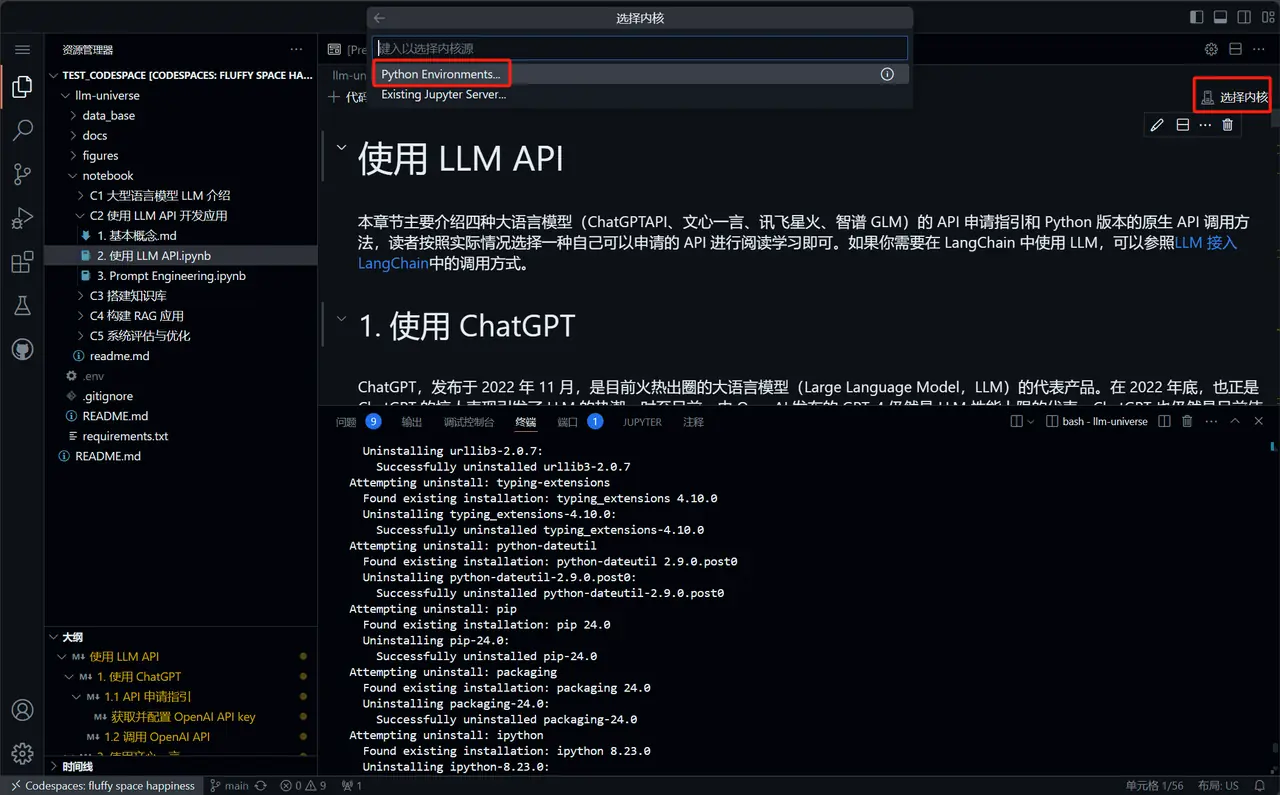
-
Click
选择 PythonThen enter the environment list and select the environment we configuredllm-universe。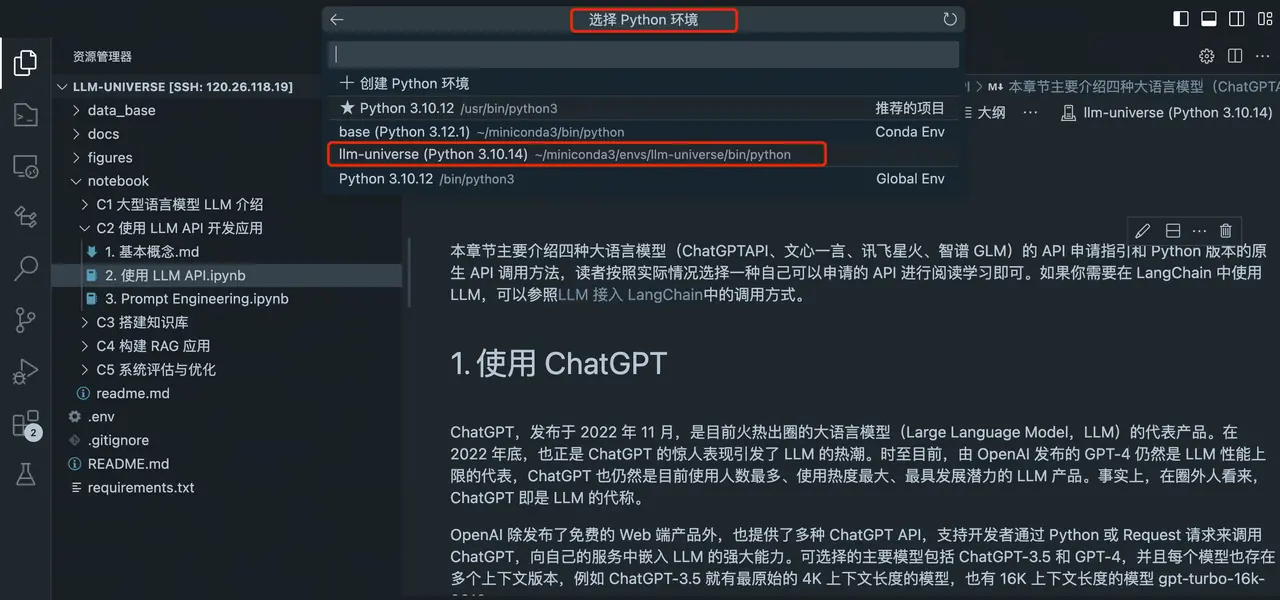
We can then develop using our Python environment in Jupyter Notebook.