**DeepSeek, created by China DeepSeek, has set off a "Made in China Intelligent" storm around the world! This revolutionary app not only topped the App Store free charts in both China and the United States, but also swept the global market with an astonishing record of four times more downloads in a single day than ChatGPT. With only US$5 million in R&D investment, it has completely surpassed the multi-billion-dollar AI projects of Silicon Valley giants such as OpenAI and Google, and used its hard-core technical strength to interpret the efficiency of "Chinese-style innovation"! This small-scale technological counterattack has not only refreshed the global AI industry landscape, but also allowed the world to witness the disruptive power of Eastern wisdom. **
**This article will teach you how to deploy DeepSeek locally so that you can use DeepSeek anytime and anywhere. **
liunx deployment
Solution 1: Use Ollama for rapid deployment (recommended for personal/development use)
Ollama is currently the simplest local model running framework that automatically handles dependencies and GPU acceleration.
1. Install Ollama
Open a terminal and execute the following script:
2. Start the service and run DeepSeek
Select the model version according to your video memory size (take DeepSeek-R1 as an example):
- Version 1.5b (available with integrated graphics/core graphics):
ollama run deepseek-r1:1.5b - 7b version (at least 8G video memory):
ollama run deepseek-r1:7b - 14b version (at least 12G video memory):
ollama run deepseek-r1:14b
After entering the command, the system will automatically download the model and enter the conversation mode.
3. API call
Ollama defaults to11434The port opens the API service, which you can call through Python:
Option 2: Use vLLM deployment (recommended for high-performance/product deployment)
If you need extremely high throughput, or need to use it in a production environment, vLLM is a better choice.
1. Prepare the environment
It is recommended to use Conda to create a virtual environment and install PyTorch with CUDA support:
2. Download model
Download the weights file for DeepSeek-R1 from Hugging Face or ModelScope.
3. Start the OpenAI compatible server
Option 3: Deploy using Docker (environment isolation)
If you prefer to use a containerized solution, you can start DeepSeek with the web interface (Open WebUI) using the following command:
*Note: This solution requires you to first install Ollama according to solution 1. *
Troubleshooting
- Out of Video Memory (OOM): If startup fails, please try to use a version with smaller parameters (such as 1.5b or 7b), or turn on the quantized version (GGUF/AWQ).
- Driver issue: Please make sure the NVIDIA driver is installed. implement
nvidia-smiCheck whether the GPU is recognized normally. - Permission issue: If
curlThe installation failed, please add before the commandsudo。
window deployment
1.Ollama download and install
Ollama is a lightweight local AI model running framework that can run various open source large language models locally (such as Llama, Mistral, etc.)
Browser input URL: https://ollama.com/
Select a system to download
After installation, Ollama is already running. It is a CMD command tool. We can enter ollama on the command line to verify whether the installation is successful.
If the content in the picture below appears, it means the download is successful.
Install the DeepSeek-r1 model Still on the Ollama website just now, select the Model module and select the deepseek-r1 model
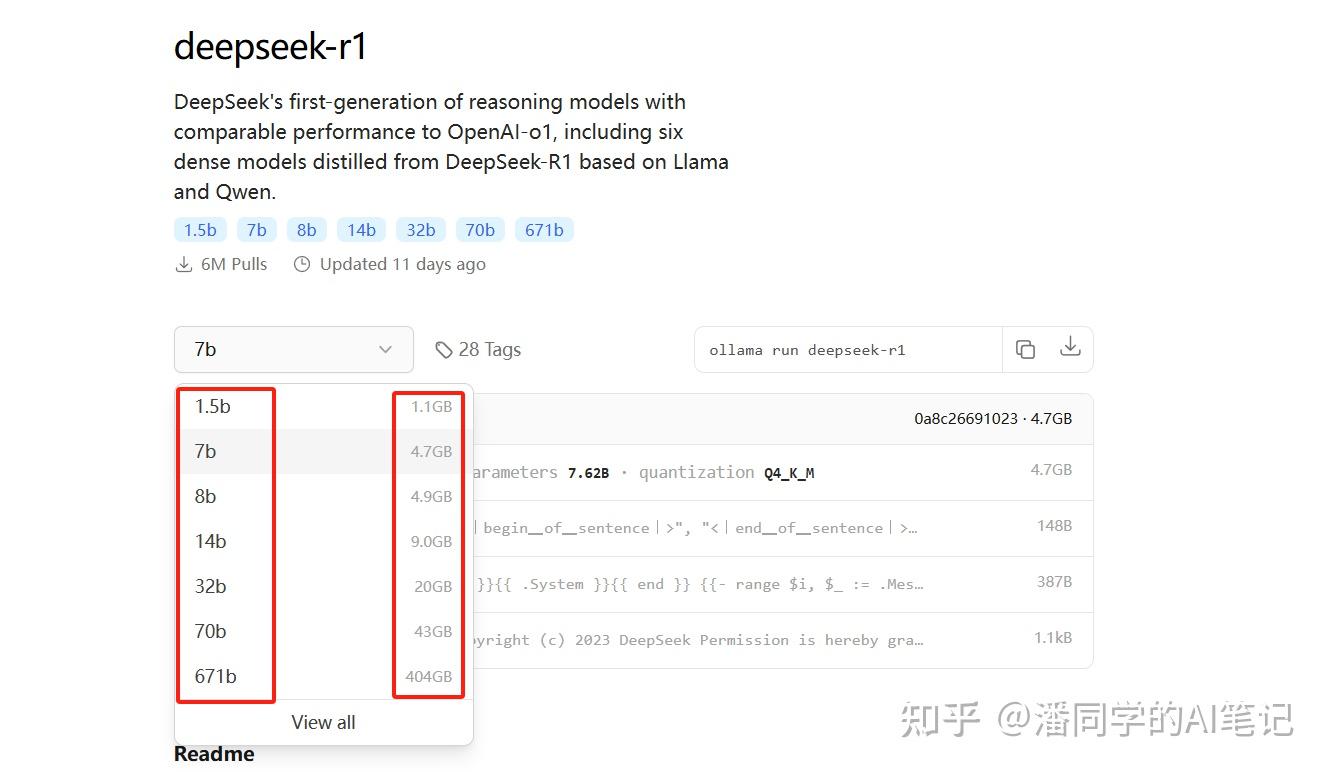
There are many versions found in the search, the difference is that the parameters are different.
1.5b,7b,8b,14b,32b,70b,671b
The memory size required for each version is different.
If your computer has 8G of running memory, you can download 1.5b, 7b, and 8b distilled models.
If your computer has 16G of running memory, you can download the 14b distilled model.
I choose the 14b model here. The larger the parameters, the better the effect of using DeepSeek.
Use ollama run deepseek-r1:14b to download
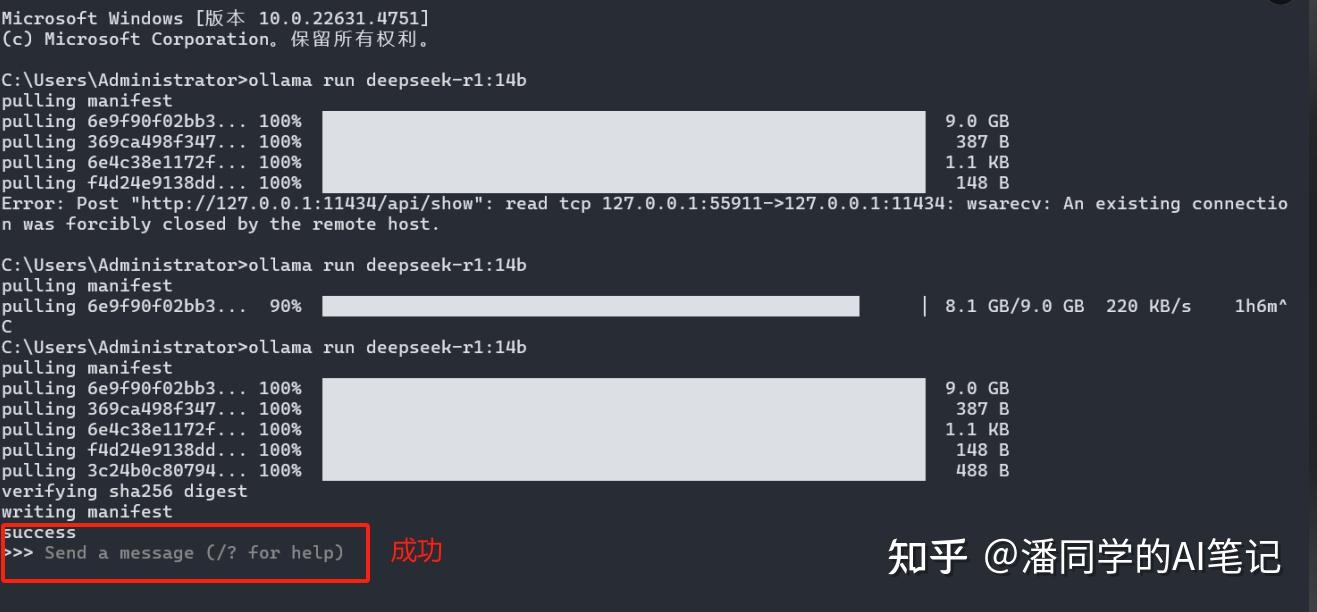
Here I failed the first time, so I tried twice before I succeeded.
We can also enter ollama list in the command line to check whether the model is successfully downloaded. The content in the figure below indicates that the download is successful.

Enter ollama run deepseek-r1:14b to run the model
After successful startup, we can enter the questions we want to ask. The model will first perform in-depth thinking (that is, where the think tag is included), and after the thinking is completed, the results of our questions will be fed back.

Note: Since ollama downloads the model to the C drive by default, if your C drive space is as stretched as mine

Then we need to change the download location of the model
Edit environment variables
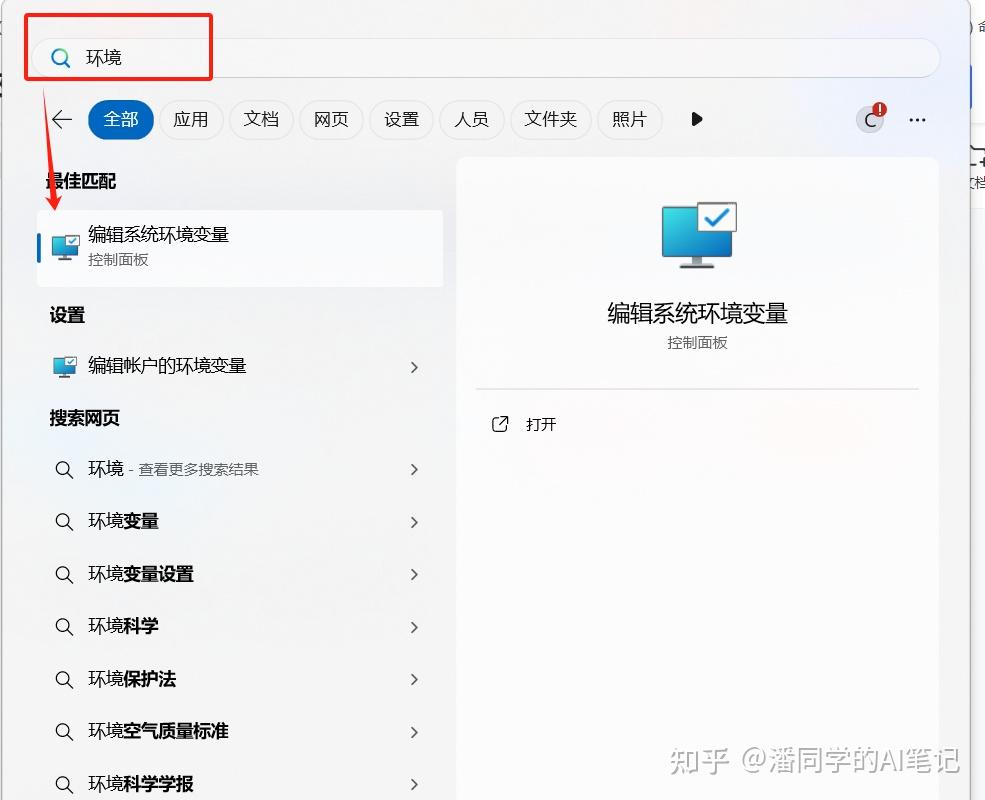
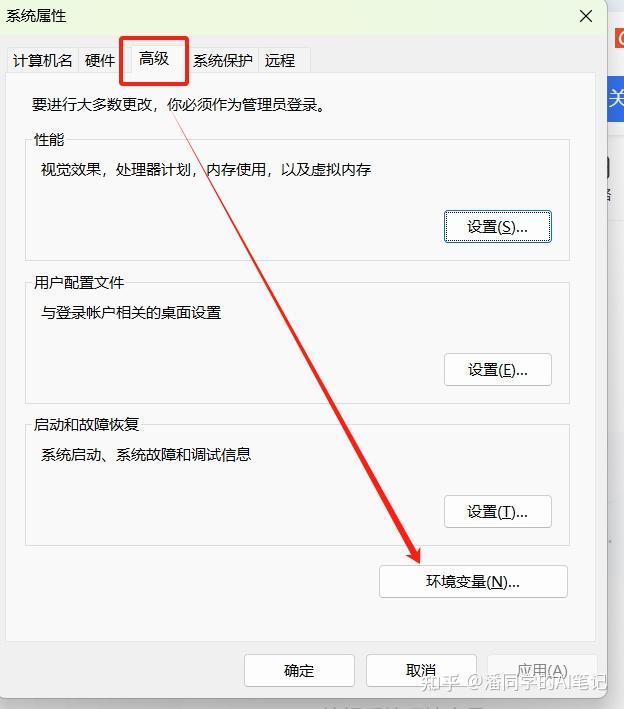
Create a new system environment variable
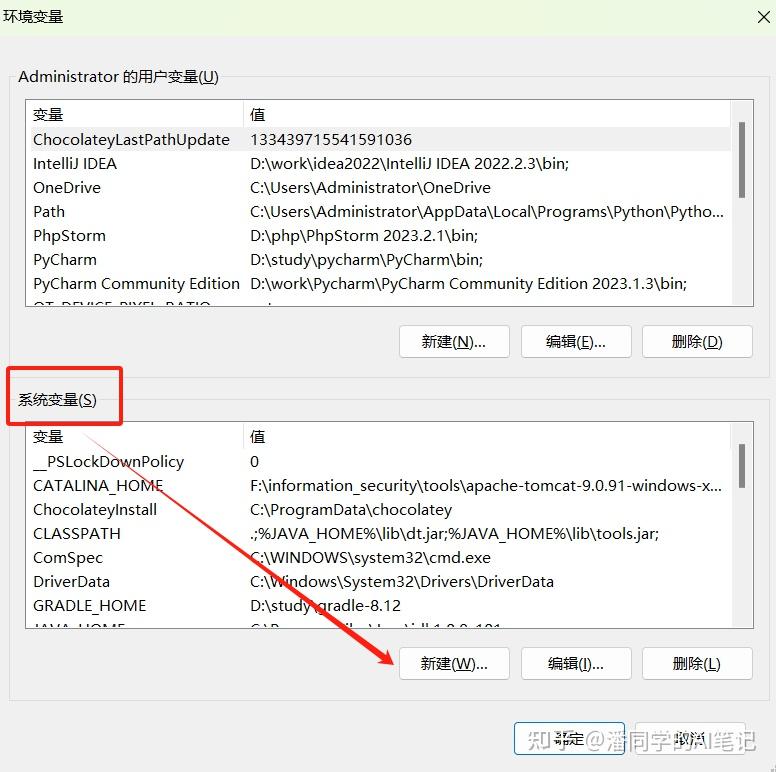
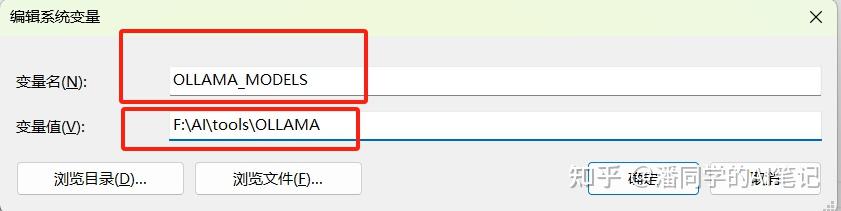
Please be sure to write OLLAMA_MODELS in the variable name
Then the variable value is the path to which you downloaded the model
Then you also need to go to the user environment variables and add two new environment variables
OLLAMA_HOST:0.0.0.0
OLLAMA_ORIGINS:*
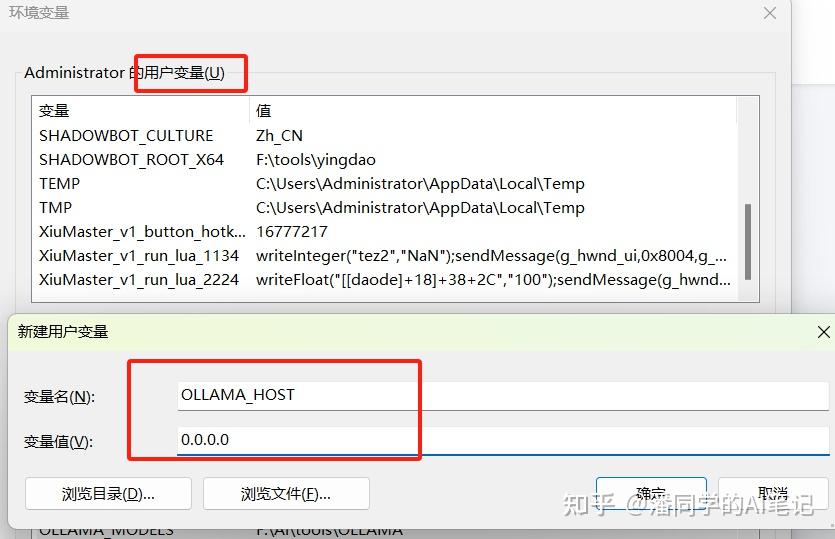
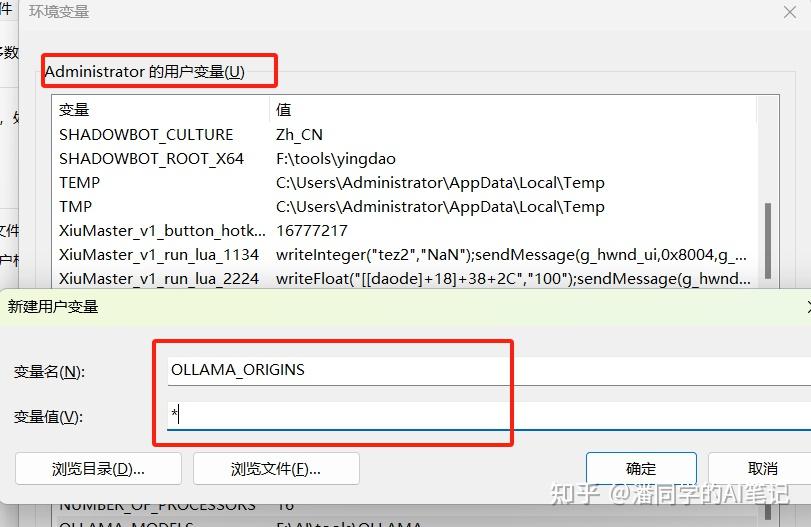
After setting everything, save it and restart ollama
2.chatBox download and install
Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
After we download the model through ollama, we can use deepseek on the command line, but the form of the command line is still a bit unsightly, so we can use chatBox, which has a beautiful UI and can be used as long as it is connected to ollama's API.
It can also be downloaded on multiple platforms. I chose windows download here.
After the installation starts, click Settings
Model provider chooses ollama API
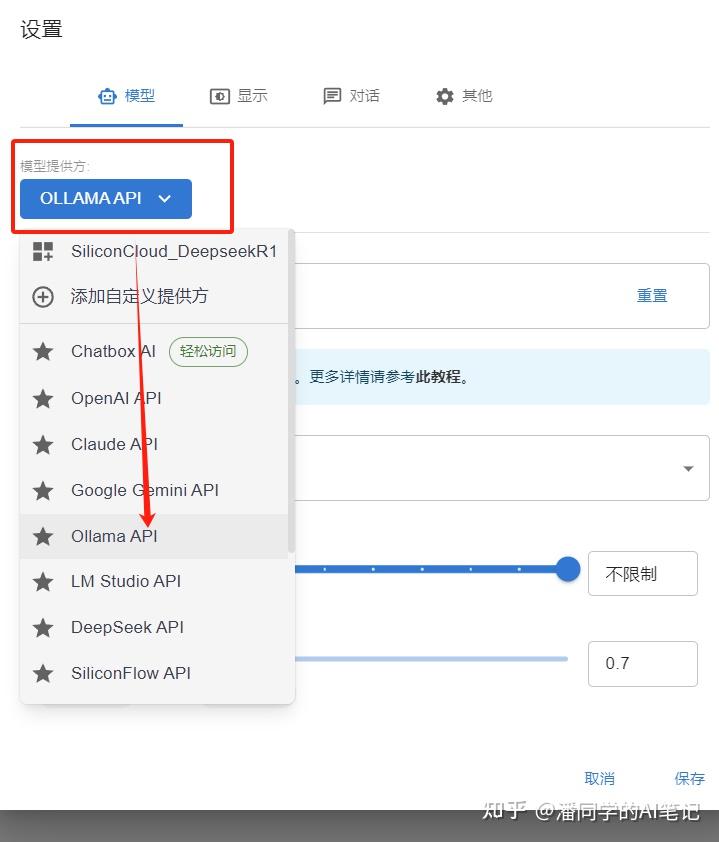
Then now you can select the model
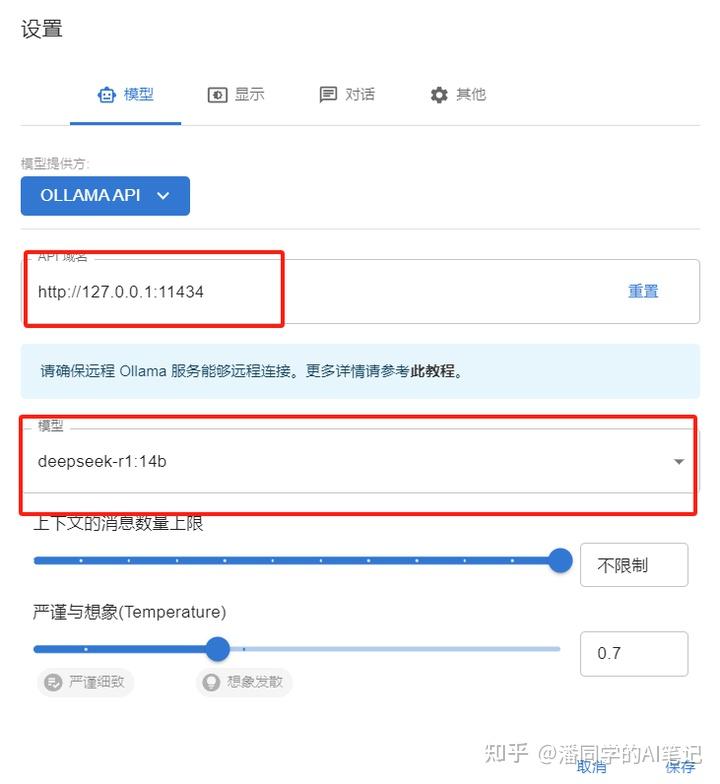
can be used successfully
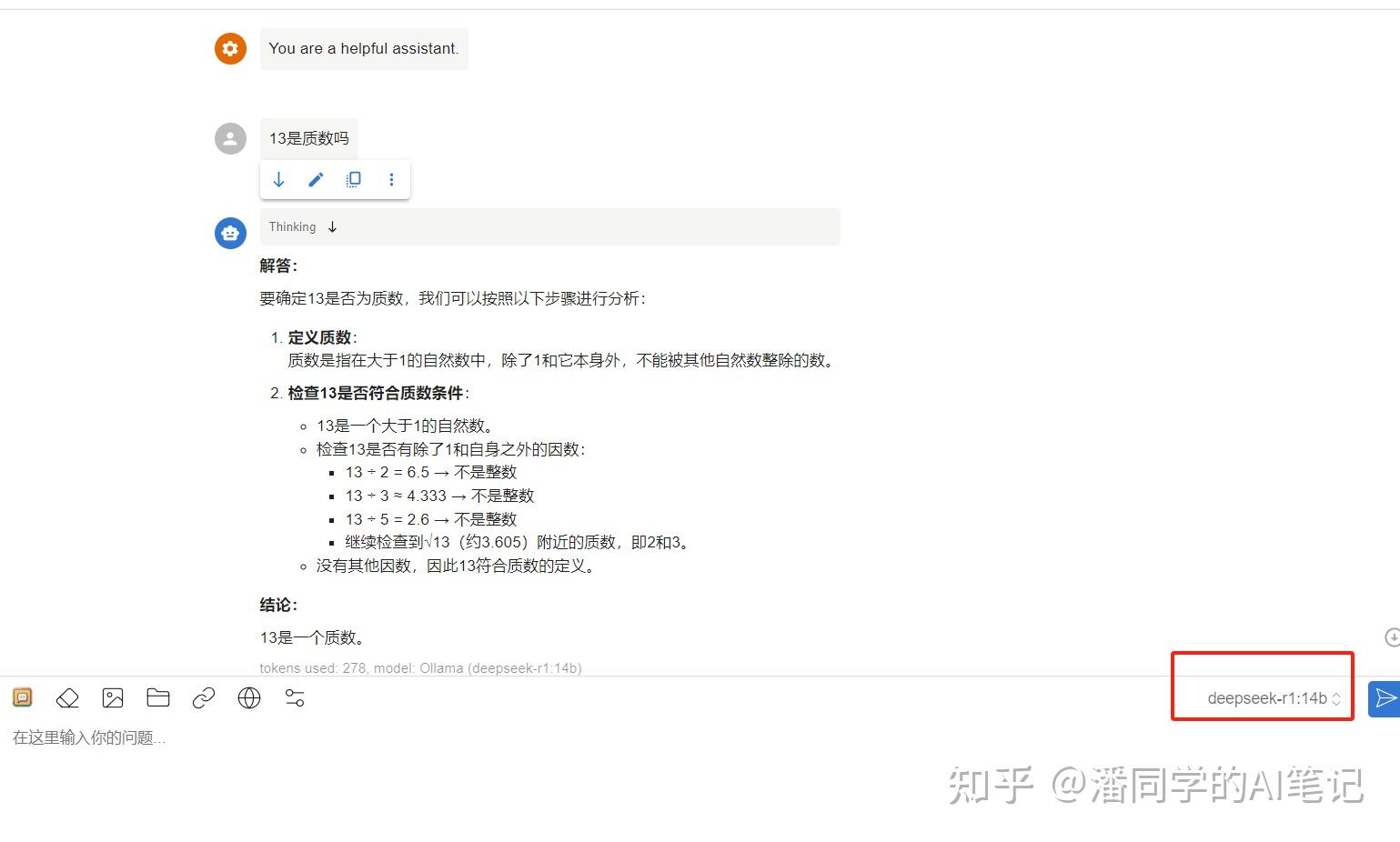
**Note: When choosing the size of the distillation model, you need to choose it based on the actual situation of your computer. This will affect the speed and effect of the model's answer. **